|
|
@@ -1,445 +0,0 @@
|
|
|
-# Abstract
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-# Introduction
|
|
|
-
|
|
|
-> ##### Rescue Robot
|
|
|
->
|
|
|
-> - What is rescue robots & some use cases of rescue robots
|
|
|
-> - Existed control methods of robots
|
|
|
-
|
|
|
-In recent years, natural disasters such as earthquakes, tsunamis and potential nuclear, chemical, biological and explosives have seriously threatened the safety of human life and property. While the number of various disasters has increased, their severity, diversity and complexity have also gradually increased. The 72h after a disaster is the golden rescue time, but the unstructured environment of the disaster site makes it difficult for rescuers to work quickly, efficiently and safely.
|
|
|
-
|
|
|
-Rescue robots have the advantages of high mobility and handling breaking capacity, can work continuously to improve the efficiency of search and rescue, and can achieve the detection of graph, sound, gas and temperature within the ruins by carrying a variety of sensors, etc.
|
|
|
-Moreover, the robot rescue can assist or replace the rescuers to avoid the injuries caused by the secondary collapse and reduce the risk of rescuers. Therefore, rescue robots have become an important development direction.
|
|
|
-
|
|
|
-In fact, rescue robots have been put to use in a number of disaster scenarios. The Center for Robot-Assisted Search and Rescue (CRASAR) used rescue robots for Urban Search and Rescue (USAR) task during the World Trade Center collapse in 2001 \cite{Casper:2003tk} and has employed rescue robots at multiple disaster sites in the years since to assist in finding survivors, inspecting buildings and scouting the site environment etc \cite{Murphy:2012th}. Anchor Diver III was utilized as underwater support to search for bodies drowned at sea after the 2011 Tohoku Earthquake and Tsunami \cite{Huang:2011wq}.
|
|
|
-
|
|
|
-Considering the training time and space constraints for rescuers \cite{Murphy:2004wl}, and the goal of efficiency and fluency collaboration \cite{10.1145/1228716.1228718}, the appropriate human-robot interaction approach deserves to be investigated. Some of the existing human-computer interaction methods are Android software \cite{Sarkar:2017tt} \cite{Faisal:2019uu}, gesture recognition\cite{Sousa:2017tn} \cite{10.1145/2157689.2157818} \cite{Nagi:2014vu}, facial voice recognition \cite{Pourmehr:2013ta}, adopting eye movements \cite{Ma:2015wu}, Augmented Reality(AR)\cite{SOARES20151656} and Virtual Reality(VR), etc.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-> ##### VR and robot
|
|
|
->
|
|
|
-> ###### What is VR
|
|
|
->
|
|
|
->
|
|
|
->
|
|
|
-> ###### VR Advantage
|
|
|
->
|
|
|
-> - general advantages
|
|
|
->- advantage regarding robots
|
|
|
->
|
|
|
->###### VR limatation and challenges
|
|
|
->
|
|
|
-> - disadvantages
|
|
|
->- challenges: improve the level of human-computer integration.
|
|
|
-> - There remains a need to ...
|
|
|
-
|
|
|
-Among them, VR has gained a lot of attention due to its immersion and the interaction method that can be changed virtually. VR is no longer a new word. With the development of technology in recent years, VR devices are gradually becoming more accessible to users. With the improvement of hardware devices, the new generation of VR headsets have higher resolution and wider field of view. And in terms of handle positioning, with the development of computer vision in the past few years, VR devices can now use only the four cameras mounted on the VR headset to achieve accurate spatial positioning, and support hand tracking, accurately capturing every movement of hand joints. While VR are often considered entertainment devices, VR brings more than that. It plays an important role in many fields such as entertainment, training, education and medical care.
|
|
|
-
|
|
|
-The use of VR in human-computer collaboration also has the potential. In terms of reliability, VR is reliable as a novel alternative to human-robot interaction. The interaction tasks that users can accomplish with VR devices do not differ significantly from those using real operating systems\cite{Villani:2018ub}. In terms of user experience and operational efficiency, VR displays can provide users with stereo viewing cues, which makes collaborative human-robot interaction tasks in certain situations more efficient and performance better \cite{Liu:2017tw}. A novel VR-based practical system for immersive robot teleoperation and scene exploration can improve the degree of immersion and situation awareness for the precise navigation of the robot as well as the interactive measurement of objects within the scene. In contrast, this level of immersion and interaction cannot be reached with video-only systems \cite{Stotko:2019ud}.
|
|
|
-
|
|
|
-However, there remains a need to explore human-computer interaction patterns and improve the level of human-computer integration\cite{Wang:2017uy}. Intuitive and easy-to-use interaction patterns can enable the user to explore the environment as intentionally as possible and improve the efficiency of search and rescue. The appropriate interaction method should cause less mental and physical exhaustion, which also extends the length of an operation, making it less necessary for the user to frequently exit the VR environment for rest.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-> ##### What I have done (overview)
|
|
|
->
|
|
|
-> ###### Unity Project
|
|
|
->
|
|
|
-> - main goal
|
|
|
-> - 4 modes
|
|
|
->
|
|
|
-> - test scenes
|
|
|
->
|
|
|
->
|
|
|
->
|
|
|
-> ###### User Study
|
|
|
->
|
|
|
-> - Testing process
|
|
|
->
|
|
|
-> - General content of the survey
|
|
|
-
|
|
|
-For this purpose, this paper presents a preliminary VR-based system for the simulation of ground rescue robots with four different modes of operation and corresponding test scenes imitating a post-disaster city. The test scene simulates a robot collaborating with Unity to construct a virtual 3D scene. The robot has a simulated LiDAR remote sensor, which makes the display of the scene dependent on the robot's movement. In order to find an interaction approach that is as intuitive and low mental fatigue as possible, a user study was executed after the development was completed.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-> ##### Paper Architecture
|
|
|
-
|
|
|
-Chapter \ref{related} talks about some of the research involving the integration of VR and human-computer interaction.
|
|
|
-
|
|
|
-Chapter \ref{*i*mplementation} provides details of the purposed system, including the techniques used for the different interaction modes and the structure of the test scenes.
|
|
|
-Chapter \ref{evaluate} will talk about the design and process of user study.
|
|
|
-
|
|
|
-Chapter \ref{result} presents the results of the user study and analyzes the advantages and disadvantages of the different modes of operation and the directions for improvement.
|
|
|
-
|
|
|
-Finally, in Chapter \ref{conclusion}, conclusions and future work are summarized.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-# Related Work
|
|
|
-
|
|
|
-In this chapter, some research on the integration of VR and human-computer interaction will be discussed. The relevant literature and its contributions will be briefly presented. The topic of VR and human-computer integration is an open research with many kinds of focus perspectives.
|
|
|
-Robotic manipulation platforms combined with virtual worlds have several application scenarios. It can be used, for example, to train operators or to collaborate directly with real robots. Elias Matsas et al. \cite{Matsas:2017aa} provided a VR-based training system using hand recognition. Kinect cameras are used to capture the user's positions and motions, and virtual user models are constructed in the VR environment based on the collected data to operate robots as well as virtual objects, such as buttons. Users will learn how to operate the robot in a VR environment. The framework of VR purposed by Luis Pérez et al. \cite{Perez:2019ub} is applied to train operators to learn to control the robot. Since the environment does not need to change in real time, but rather needs to realistically recreate the factory scene, the VR scene here is not reconstructed in a way that it is captured and rendered in real time. Rather, a highly accurate 3D environment was reconstructed in advance using Blender after being captured with a 3D scanner.
|
|
|
-
|
|
|
-Building 3D scenes in virtual worlds based on information collected by robots is also a research highlight. Wang, et al. \cite{Wang:2017uy} were concerned with the visualization of the rescue robot and its surroundings in a virtual environment. The proposed human-robot interaction system uses incremental 3D-NDT map to render the robot's surroundings in real time. The user can view the robot's surroundings in a first-person view through the HTC-Vive and send control commands through the handle's arrow keys. A novel VR-based practical system is presented in \cite{Stotko:2019ud} consisting of distributed systems to reconstruct 3D scene. The data collected by the robot is first transmitted to the client responsible for reconstructing the scene. After the client has constructed the 3d scene, the set of actively reconstructed visible voxel blocks is sent to the server responsible for communication, which has a robot-based live telepresence and teleoperation system. This server will then broadcast the data back to the client used by the operator, thus enabling an immersive visualization of the robot within the scene.
|
|
|
-
|
|
|
-Others are more concerned about the manipulation of the robotic arm mounted on the robot. Moniri et al. \cite{Moniri:2016ud} provided a VR-based operating model for the robotic arm. The user wearing a headset can see a simulated 3D scene at the robot's end and send pickup commands to the remote robot by clicking on the target object with the mouse. The system proposed by Ostanin et al. \cite{Ostanin:2020uo} is worth mentioning. Although their proposed system for operating a robotic arm is based on mixed reality(MR), the article is highly relevant to this paper, considering the high relevance of MR and VR and the proposed system detailing the combination of ROS and robotics. In their system,the ROS Kinect was used as middleware and was responsible for communicating with the robot and the Unity side. The user can control the movement of the robot arm by selecting predefined options in the menu. In addition, the orbit and target points of the robot arm can be set by clicking on a hologram with a series of control points.
|
|
|
-
|
|
|
-# Implementation
|
|
|
-
|
|
|
-% summary
|
|
|
-
|
|
|
-In this chapter, the tools and techniques used in building this human-computer collaborative VR-based system are described. The focus will be on interaction techniques for different modes of operation. In addition, the setup of the robot and the construction of test scenes will also be covered in this chapter.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## 1. Overview
|
|
|
-
|
|
|
-> - the purpose of the unity project
|
|
|
-> - Components of the project: 4 operation modes & test Scene
|
|
|
-
|
|
|
-The main goal of this work is to design and implement a VR-based human-robot collaboration system with different methods of operating the robot in order to find out which method of operation is more suitable to be used to control the rescue robot. Further, it is to provide some basic insights for future development directions and to provide a general direction for finding an intuitive, easy-to-use and efficient operation method. Therefore, the proposed system was developed using Unity, including four modes of operation and a corresponding test environment for simulating post-disaster scenarios. In each operation mode, the user has a different method to control the robot. In addition, in order to better simulate the process by which the robot scans its surroundings and the computer side cumulatively gets a reconstructed 3D virtual scene, the test environment was implemented in such a way that the picture seen by the user depends on the robot's movement and the trajectory it travels through.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## 2. System Architecture
|
|
|
-
|
|
|
-> - Compurter Information: CPU,GPU
|
|
|
->
|
|
|
-> - HTC Vive
|
|
|
->
|
|
|
-> - ROS and Robot
|
|
|
->
|
|
|
-> - Unity VR engine & SteamVR
|
|
|
->
|
|
|
->
|
|
|
-
|
|
|
-The proposed system runs on a computer with the Windows 10 operating system. This computer has been equipped with an Intel Core i7-8700K CPU, 32 GB RAM as well as a NVIDIA GTX 1080 GPU with 8 GB VRAM. HTC Vive is used as a VR device. It has a resolution of 1080 × 1200 per eye, resulting in a total resolution of 2160 × 1200 pixels, a refresh rate of 90 Hz, and a field of view of 110 degrees. It includes two motion controllers and uses two Lighthouses to track the position of the headset as well as the motion controllers.
|
|
|
-
|
|
|
-Unity was chosen as the platform to develop the system. Unity is a widely used game engine with a Steam VR plugin \footnote{https://assetstore.unity.com/packages/tools/integration/steamvr-plugin-32647}, which allows developers to focus on the VR environment and interactive behaviors in programming, rather than specific controller buttons and headset positioning, making VR development much simpler. Another reason why Unity was chosen as a development platform was the potential for collaboration with the Robot Operating System (ROS), a frequently used operating system for robot simulation and manipulation, which is flexible, low-coupling, distributed, open source, and has a powerful and rich third-party feature set. In terms of collaboration between Unity and ROS, Siemens provides open source software libraries and tools in C\# for communicating with ROS from .NET applications \footnote{https://github.com/siemens/ros-sharp}. Combining ROS and Unity to develop a collaborative human-robot interaction platform proved to be feasible\cite{Whitney:2018wk}. Since the focus of this paper is on human-robot interaction, collaboration and synchronization of ROS will not be explored in detail here.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## 3. Robot
|
|
|
-
|
|
|
-> camera
|
|
|
->
|
|
|
-> radar
|
|
|
->
|
|
|
-> layer change => collider
|
|
|
->
|
|
|
-> information
|
|
|
-
|
|
|
-To simulate the process of a robot using a LiDAR remote sensor to detect the real environment and synchronise it to Unity, a sphere collision body was set up on the robot. The robot will transform the Layers of the objects in the scene into visible Layers by collision detection and a trigger event (onTriggerEnter function). The robot's driving performance, such as the number of collisions, average speed, total distance, etc., will be recorded in each test. The detailed recorded information can be seen in Fig.\ref{fig:uml}. The movement of the robot depends on the value of the signal that is updated in each mode. In addition, the robot's Gameobject has the NavMeshAgent \footnote{https://docs.unity3d.com/ScriptReference/AI.NavMeshAgent.html} component, which supports the robot's navigation to the specified destination with automatic obstacle avoidance in the test scene. The virtual robot has three cameras. One of the cameras is a simulation of a surveillance camera mounted on the robot, which can see all the items in the scene, although the distant items are not yet detected by LiDAR. Two of these camera are set up in such a way that they can only see the area detected by the robot's LiDAR remote sensor. Each camera captures what it sees and modifies the bound image bound in real time. The four operation modes described later all use the camera viewport as a monitoring screen by rendering the camera viewport on UI canvas.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## 4. Interaction techniques
|
|
|
-
|
|
|
-This system has 4 different approaches to control the robot. Each mode has its own distinctive features:
|
|
|
-
|
|
|
-```latex
|
|
|
-\begin{enumerate}
|
|
|
-\item In Handle Mode the user will send control commands directly using the motion controller.
|
|
|
-\item In Lab Mode a simulated lab is constructed in the VR environment and the user will use virtual buttons in the lab to control the rescue robot.
|
|
|
-\item In Remote Mode the user can set the driving destination directly.
|
|
|
-\item In UI Mode the user has a virtual menu and sends commands via rays from the motion controller.
|
|
|
-\end{enumerate}
|
|
|
-```
|
|
|
-
|
|
|
-In order to improve the reusability of the code and to facilitate the management of subsequent development, the classes that manage the interaction actions of each mode implement the same interface. A graphical representation of the system structure is given in the UML activity diagram in Fig.\ref{fig:uml}.
|
|
|
-
|
|
|
-```latex
|
|
|
-\begin{figure}[h]
|
|
|
- \centering
|
|
|
- \includegraphics[height=12cm]{graphics/uml.png}
|
|
|
- \caption{UML Class diagram for the main structure of the system}
|
|
|
- \label{fig:uml}
|
|
|
-\end{figure}
|
|
|
-```
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### 1. Handle Mode
|
|
|
-
|
|
|
-> - main feature
|
|
|
-> - functions: how to move robot, camera, map...
|
|
|
-> - photo
|
|
|
-
|
|
|
-In this mode, the user is controlling the robot's movement directly through the motion controller in the right hand. The touch pad of the motion controller determines the direction of rotation of the robot. The user can control the robot's driving speed by pulling the Trigger button. Fig.\ref{fig:htc} shows how to get the values from the HTC motion controller. The robot rotation direction will read the value of the touchpad X-axis. The range of values is $[-1,1]$. Forward speed reads the Trigger button passed in as a variable of type SteamVR_Action_Single, and the range of the variable is $[0,1]$. With the right-hand menu button, the surveillance screen around the robot can be turned on or off. The monitor window can be adjusted to a suitable position by dragging and rotating it. In the literature dealing with VR and human-computer collaboration, many researchers have used a similar operational approach. Therefore, as a widely used, and in a sense default operation approach, this mode was designed and became one of the proposed operation modes.
|
|
|
-
|
|
|
-```latex
|
|
|
-\begin{figure}[h]
|
|
|
- \centering
|
|
|
- \includegraphics[height=12cm]{graphics/htc.png}
|
|
|
- \caption{HTC handle illustration. }
|
|
|
- \label{fig:htc}
|
|
|
-\end{figure}
|
|
|
-```
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### 2. Lab Mode
|
|
|
-
|
|
|
-> - main feature
|
|
|
-> - functions: how to move robot, button, speed editor, auto drive 3 monitor....
|
|
|
-> - photo
|
|
|
-
|
|
|
-The original intention of designing this mode is that there is a part of the literature where the immersive human-robot collaborative framework are used to train operators how to operate the robot, avoiding risks and saving learning costs or directly as a platform for operating the robot \cite{Perez:2019ub}\cite{Matsas:2017aa}. Therefore, in this mode, a virtual laboratory environment is constructed, in which simulated buttons, controllers, and monitoring equipment are placed. The laboratory consists of two parts. The first part is the monitoring equipment: the monitoring screen is enlarged and placed at the front of the lab as a huge display. The second part is the operating console in the center of the laboratory, which can be moved by the user as desired. The user can use the buttons on the right side to lock the robot or let it walk forward automatically. In the middle of the console are two operating joysticks that determine the robot's forward motion and rotation respectively. The part that involves virtual joystick movement and button effects uses an open source github project VRtwix\footnote{https://github.com/rav3dev/vrtwix}. With the sliding stick on the left, the user can edit the speed of the robot's forward movement and rotation.
|
|
|
-
|
|
|
-##### 3. Remote Mode
|
|
|
-
|
|
|
-> - main feature
|
|
|
-> - functions: how to move robot: target(Pseudocode?) or virtural joystick. ItemPackage in Steam
|
|
|
-> - photo
|
|
|
-
|
|
|
-In this mode, the user can set the driving target point directly or control the robot by picking up the remote control that is placed on the toolbar. The target point is set by the ray emitted by the right motion controller. This process is similar to setting a teleportation point. After the target point is set, a square representing the destination is shown in the scene, and the robot will automatically travel to the set destination. The entire driving process uses the NavMeshAgent component and is therefore capable of automatic obstacle avoidance.
|
|
|
-By clicking on the menu button, a movable toolbar is opened with a remote control and a monitoring device. The remote control is a safety precaution in case the automatic navigation fails to navigate to the target point properly. The user can adjust the direction of the robot's travel by using the remote control. The pickup and auto-release parts use the ItemPackage component available in the SteamVR plugin.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### 4. UI Mode
|
|
|
-
|
|
|
-> - main feature
|
|
|
-> - functions: introcude here compositions of the UI menu
|
|
|
-> - photo
|
|
|
-
|
|
|
-The virtual menu is also an interaction method that is often used in VR, so this mode is proposed. In this mode, the user must interact with the virtual menu using the ray emitted by the right motion controller. The virtual menu is set up with buttons for the direction of movement, speed controller, and buttons to open and close the monitor screen. In addition to this, an additional follow function is added to the menu, allowing the robot to follow the user's position in the virtual world. This is intended to let the user concentrate on observing the rendered VR environment. Also, having a real robot follow the user's location in the virtual world is a novel, unique human-machine integration mode in VR. The robot's automatic navigation uses the NavMeshAgent.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## 5. Test Scene
|
|
|
-
|
|
|
-> - goal of the project: rescue robots => destroyed city,
|
|
|
-> - environment: destroyed city & Collider for test [photo]
|
|
|
-> - LiDAR layer
|
|
|
-
|
|
|
-In order to simulate the use of rescue robots in disaster scenarios, the test scenes were built to mimic the post-disaster urban environment as much as possible. The POLYGON Apocalypse\footnote{https://assetstore.unity.com/packages/3d/environments/urban/polygon-apocalypse-low-poly-3d-art-by-synty-154193}, available on the Unity Asset Store, is a low poly asset pack with a large number of models of buildings, streets, vehicles, etc. Using this resource pack as a base, additional collision bodies of the appropriate size were manually added to each building and obstacle after the pack was imported, which was needed to help track the robot's driving crash in subsequent tests.
|
|
|
-
|
|
|
-Considering that there are four modes of operation to be tested, four scenes with similar complexity, similar composition of buildings but different road conditions and placement of buildings were constructed. The similarity in complexity of the scenes ensures that the difficulty of the four tests is basically identical. The different scene setups ensure that the scene information learned by the user after one test will not make him understand the next test scene and thus affect the accuracy of the test data.
|
|
|
-
|
|
|
-The entire scene is initially invisible, and the visibility of each objects in the test scene is gradually updated as the robot drives along. Ten interactable sufferer characters were placed in each test scene. The place of placement can be next to the car, the house side and some other reasonable places.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-# Evaluation of User Experience
|
|
|
-
|
|
|
-> ##### main goal of test (Overview)
|
|
|
->
|
|
|
-> - Evaluate user experience and robot performance in different operating modes
|
|
|
-
|
|
|
-This chapter describes the design and detailed process of the user evaluation. The purpose of this user study is to measure the impact of four different modes of operation on rescue efficiency, robot driving performance, and psychological and physiological stress and fatigue, etc. For this purpose, participants are asked to find victims in a test scene using different modes of operation and to answer questionnaires after the test corresponding to each mode of operation.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## Study Design
|
|
|
-
|
|
|
-The evaluation for each mode of operation consists of two main parts. The first part is the data recorded during the process of the participant driving the robot in the VR environment to find the victims. The recorded data includes information about the robot's collision and the speed of driving etc. The rescue of the victims was also considered as part of the evaluation. The Official NASA Task Load Index (TLX) was used to measure the participants subjective workload asessments. Additionally, participants were asked specific questions for each mode and were asked to select their favorite and least favorite operation mode. In order to reduce the influence of order effects on the testl results, the Balanced Latin Square was used when arranging the test order for the four operation modes.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-## Procedure
|
|
|
-
|
|
|
-##### Demographics and Introduction
|
|
|
-
|
|
|
-> 1. inform the purpose and collected data
|
|
|
-> 2. basic demographics(google form)
|
|
|
-> 3. introduce 4 mode: verbal + show motion controller
|
|
|
-
|
|
|
-Before the beginning of the actual testing process, participants were informed of the purpose of the project, the broad process and the content of the data that would be collected. After filling in the basic demographics, the features of each of the four modes of operation and their rough usage were introduced verbally with a display of the buttons on the motion controllers.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### Entering the world of VR
|
|
|
-
|
|
|
-> 1. wear the headset
|
|
|
->
|
|
|
-> 2. familiar with the basic VR action :
|
|
|
->
|
|
|
-> - open & close Menu
|
|
|
->
|
|
|
-> - change position : teleport & raise or lower
|
|
|
->
|
|
|
-> 3. rescue 1 victim
|
|
|
-
|
|
|
-After the basic introduction part, participants would directly put on the VR headset and enter the VR environment to complete the rest of the tutorial. Considering that participants might not have experience with VR and that it would take time to learn how to operate the four different modes, the proposed system additionally sets up a practice pattern and places some models of victims in the practice scene. After entering the VR world, participants first needed to familiarize themselves with the opening and closing menu, as well as useing the motion controllers to try to teleport themselves, or raise themselves into mid-air. Finally participants were asked to interact with the victim model through virtual hands. After this series of general tutorials, participants were already generally familiar with the use of VR and how to move around in the VR world.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### Practice and evaluation of modes
|
|
|
-
|
|
|
-> 1. `foreach Mode`:
|
|
|
-> 1. practice
|
|
|
-> - try to move the robot
|
|
|
-> - try to rescue 1-2 victims
|
|
|
-> 2. enter test scene
|
|
|
-> 3. -testing-
|
|
|
-> 4. Fill out the questionnaire: google form + TLX
|
|
|
->
|
|
|
-> 2. summary part of google form:
|
|
|
-> - like/dislike most
|
|
|
-> - reason
|
|
|
-> - feedback
|
|
|
-
|
|
|
-Given the different manipulation approaches for each mode, in order to avoid confusion between the different modes, participants would then take turns practicing and directly evaluating each mode immediately afterwards.
|
|
|
-
|
|
|
-The sequence of modes to be tested is predetermined. The order effect is an important factor affecting the test results. If the order of the operational modes to be tested was the same for each participant, the psychological and physical exhaustion caused by the last operation mode would inevitably be greater. In order to minimize the influence of the order effect on the results of the test, the Balanced Latin Square with the size of four was used to arrange the test order of the four operation modes.
|
|
|
-
|
|
|
-Participants automatically entered the practice scene corresponding to the relevant operation mode in the predefined order. After attempting to rescue 1-2 victim models and the participant indicated that he or she was familiar enough with this operation mode, the participant would enter the test scene. In the test scene, participants had to save as many victims as possible in a given time limit. Participants were required to move the robot around the test scene to explore the post-disaster city and to find and rescue victims. In this process, if the robot crashes with buildings, obstacles, etc., besides the collision information being recorded as test data, participants would also receive sound and vibration feedback. The test will automatically end when time runs out or when all the victims in the scene have been rescued. Participants were required to complete the evaluation questionnaire and the NASA evaluation form at the end of each test. This process was repeated in each mode of operation.
|
|
|
-
|
|
|
-After all the tests were completed, participants were asked to compare the four operation modes and select the one they liked the most and the one they liked the least. In addition, participants could give their reasons for the choice and express their opinions as much as they wanted, such as suggestions for improvement or problems found during operation.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-# Results and discussion
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### Participants
|
|
|
-
|
|
|
-> ##### Demographics
|
|
|
->
|
|
|
-> 8 Participants
|
|
|
->
|
|
|
-> age
|
|
|
->
|
|
|
-> study
|
|
|
->
|
|
|
-> experience vr
|
|
|
-
|
|
|
-A total of 8 volunteers participated in the user study (3 females and 5 males between 22 and 32 years, mean age xxx years). Five of them were computer science students at the university. Four participants had previous experience with VR, but had played it only a few times.
|
|
|
-
|
|
|
-##### Quantitative Results
|
|
|
-
|
|
|
-Part of the data for the quantitative analysis comes from the robot's performance and testing results, which were automatically recorded by the proposed system during the tests. The other part of the data comes from the questionnaires that the participants filled out after the test.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
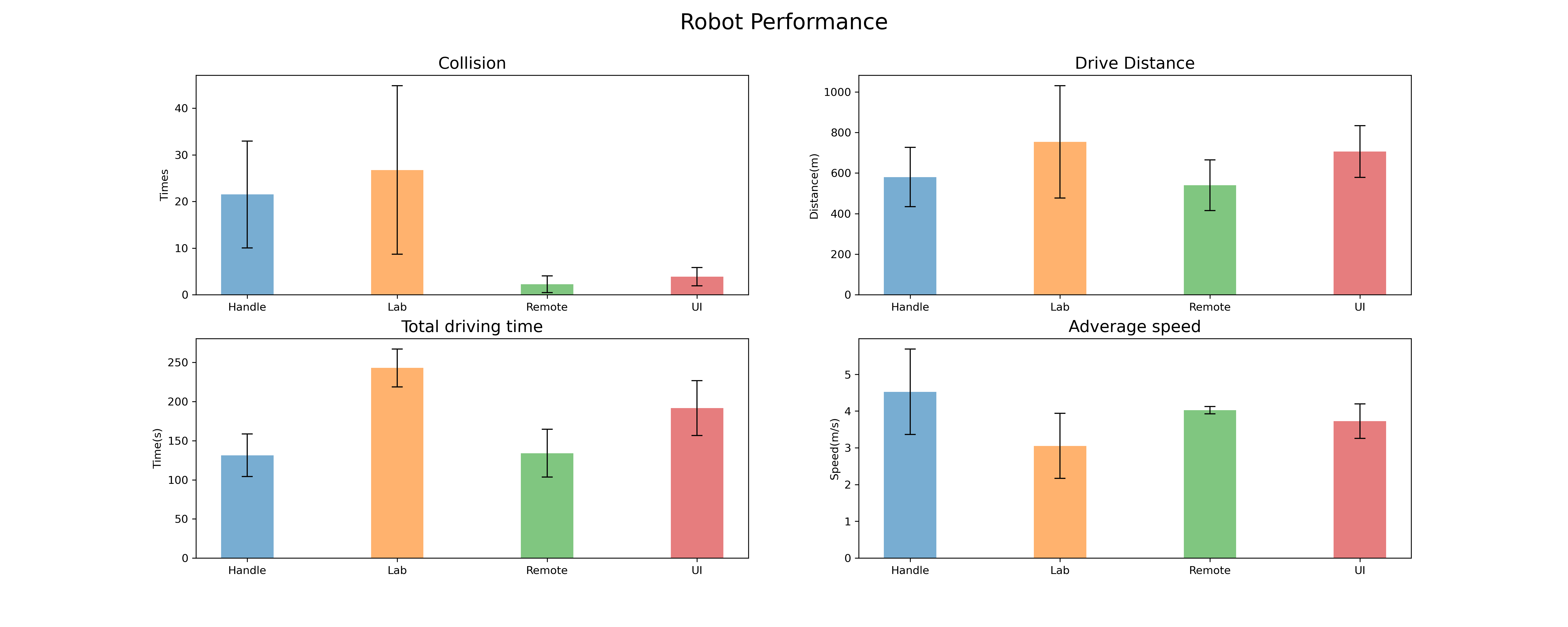
-###### Robot Performance
|
|
|
-
|
|
|
-> introduce what was recorded
|
|
|
->
|
|
|
-> [table]
|
|
|
->
|
|
|
-> analysis
|
|
|
-
|
|
|
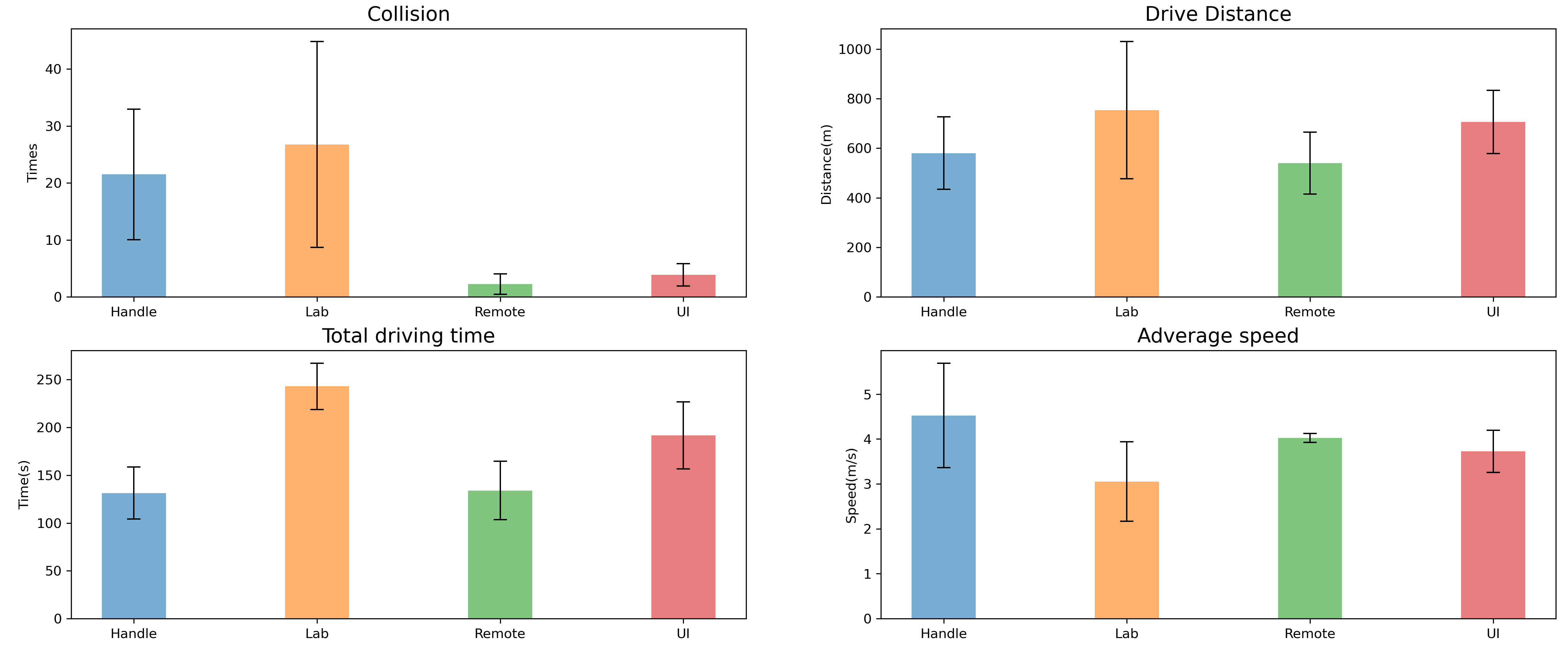
-During the test ran, these following data were recorded.
|
|
|
-
|
|
|
-% `collision`
|
|
|
-
|
|
|
-The first is the number of collisions between the robot and objects in the scene, which reflects the probability of the robot being destroyed in different operation modes. The assumption before the experiment started was that the number of collisions should be highest in lab mode as well as in handle mode. This is because the two modes involve frequent switching back and forth between the scene and the console or screen, which may result in the user not being able to concentrate on observing the obstacles in the scene. 【结果】
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
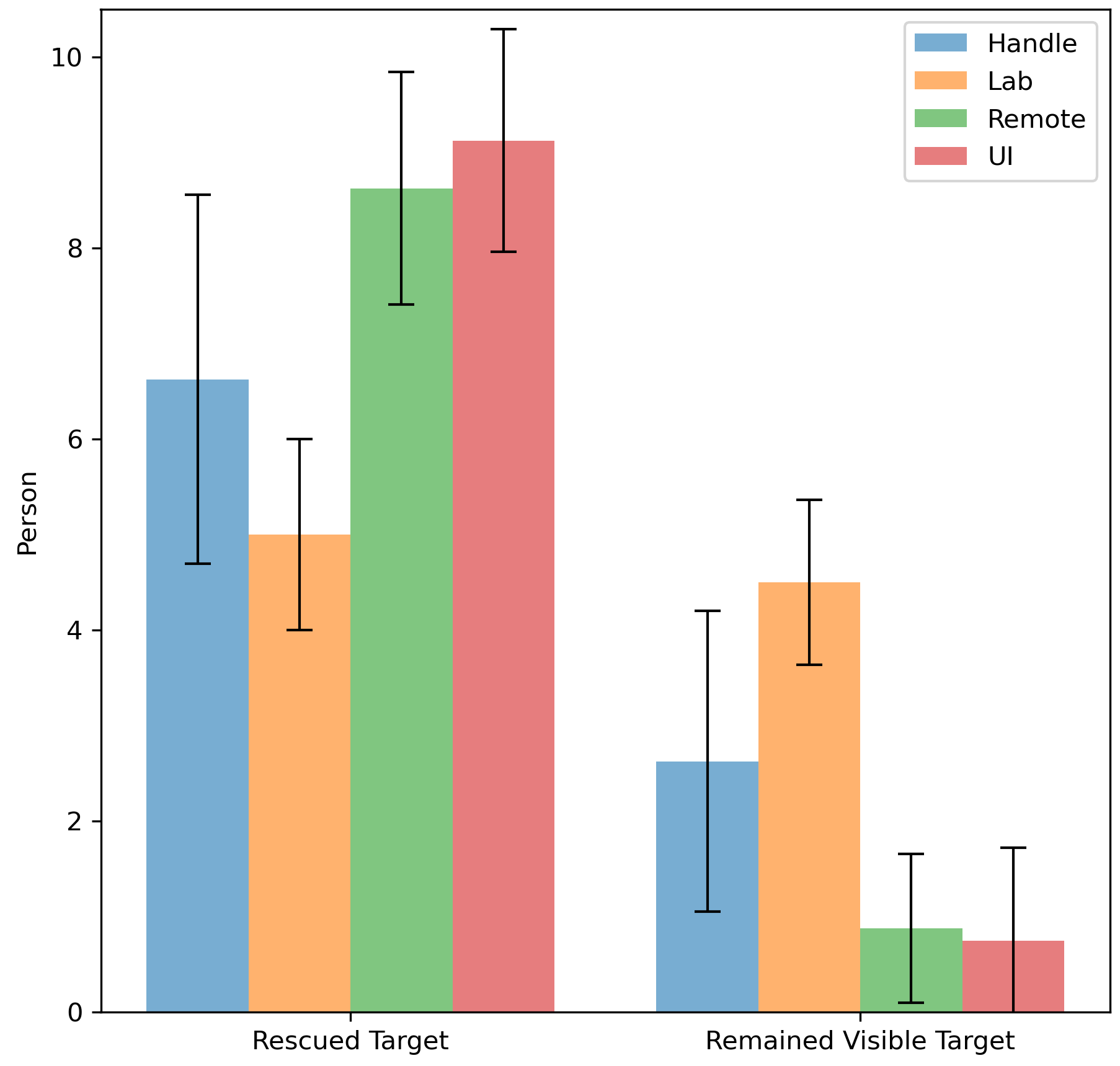
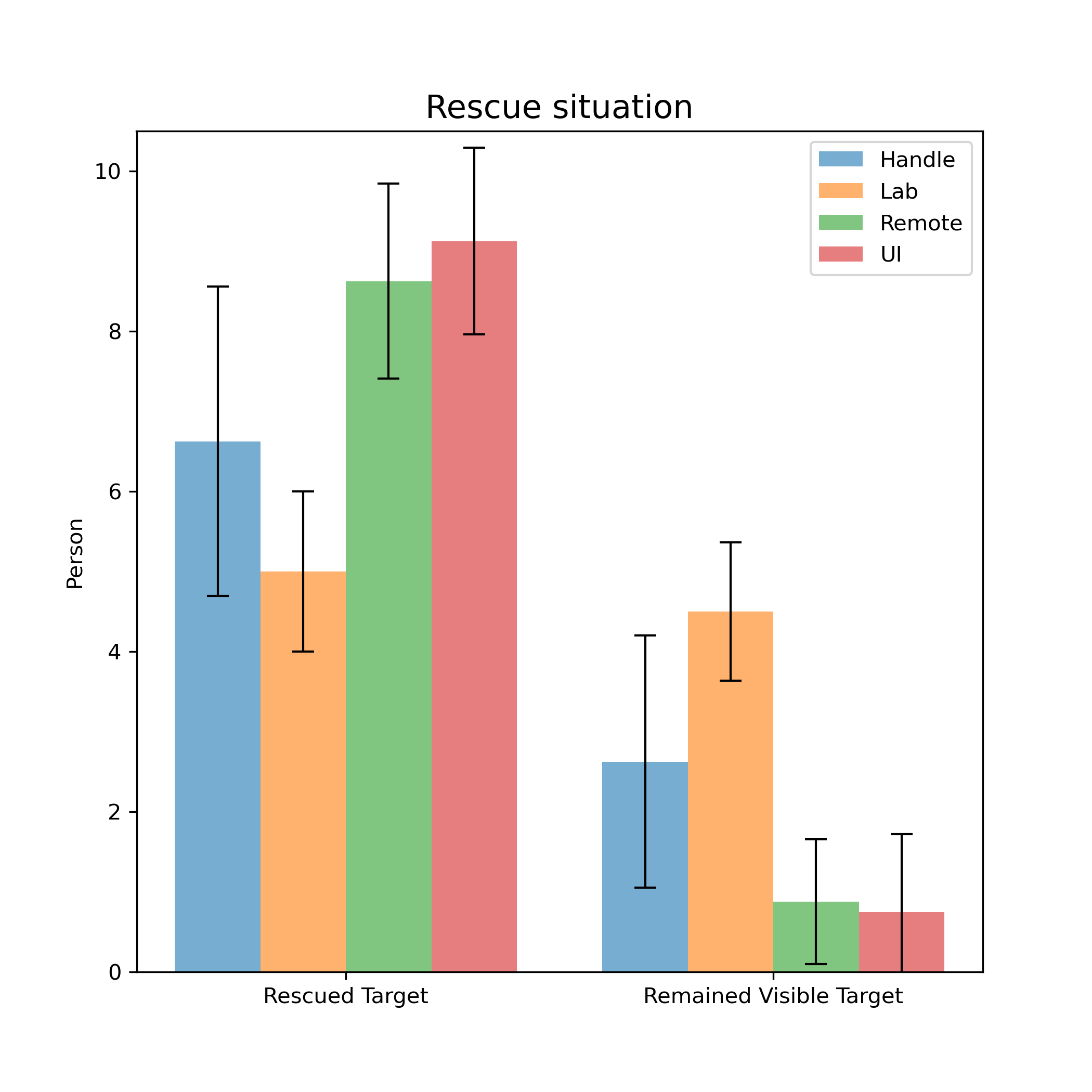
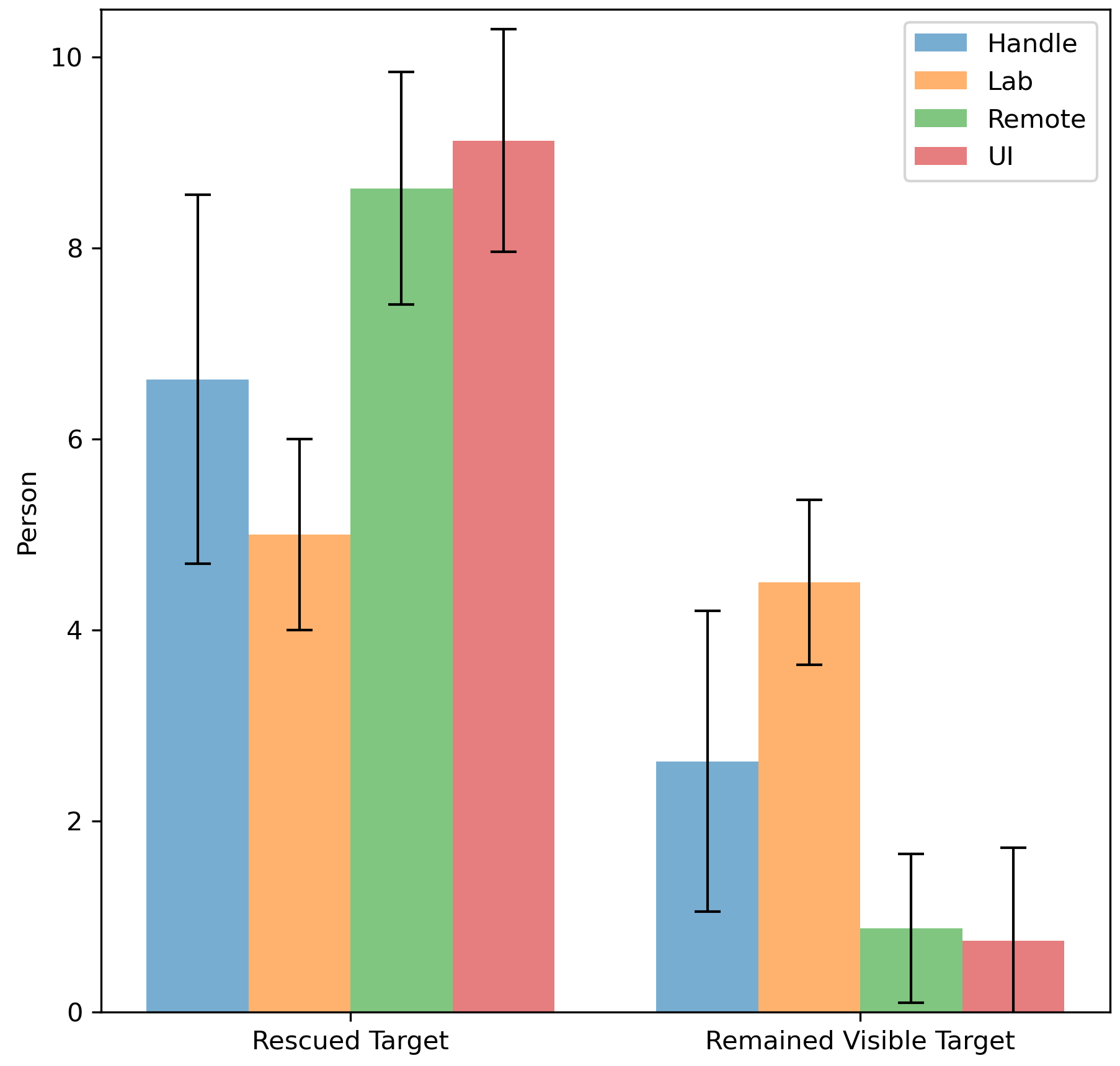
-###### Rescue situation
|
|
|
-
|
|
|
-> introduce what was recorded
|
|
|
->
|
|
|
-> [table]
|
|
|
->
|
|
|
-> analysis
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
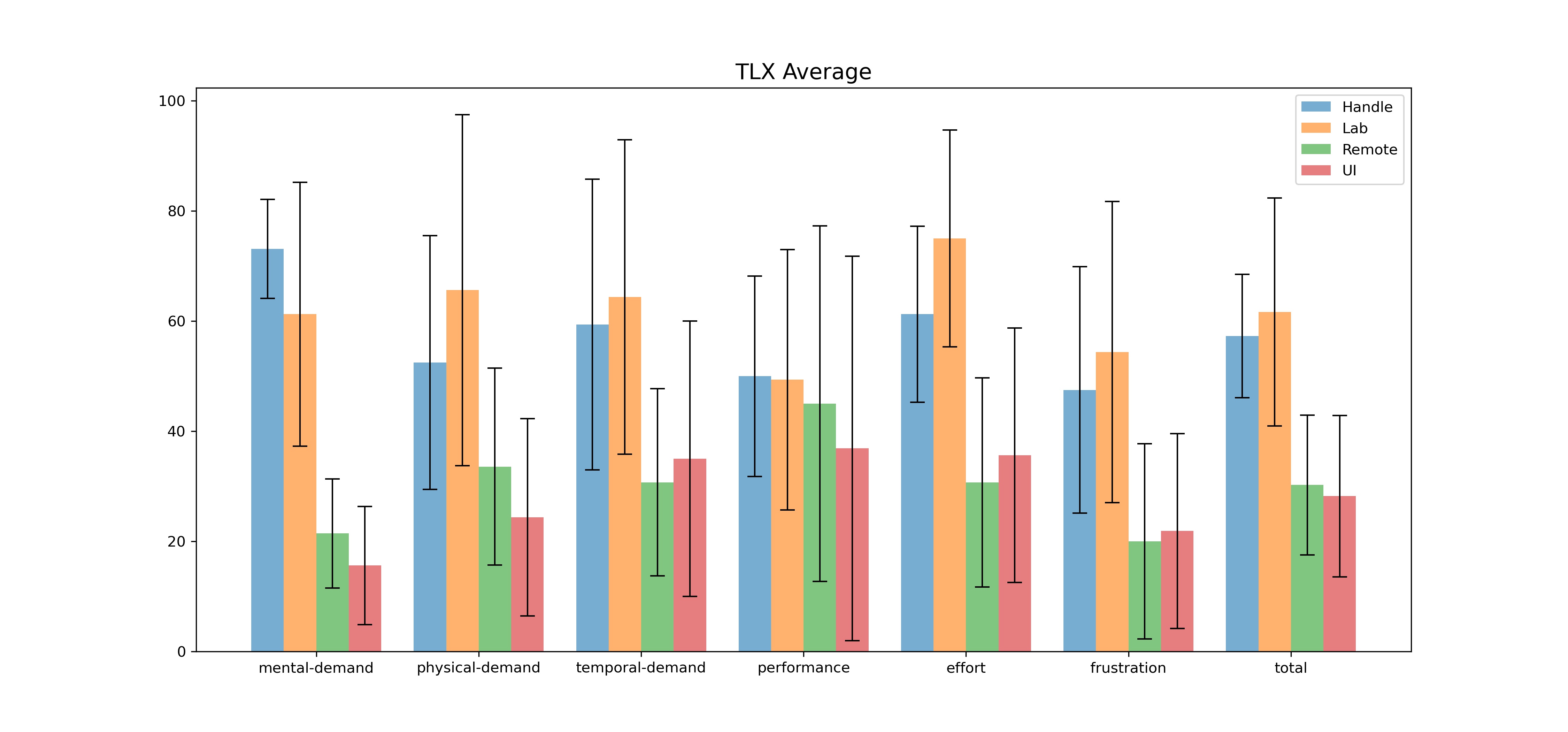
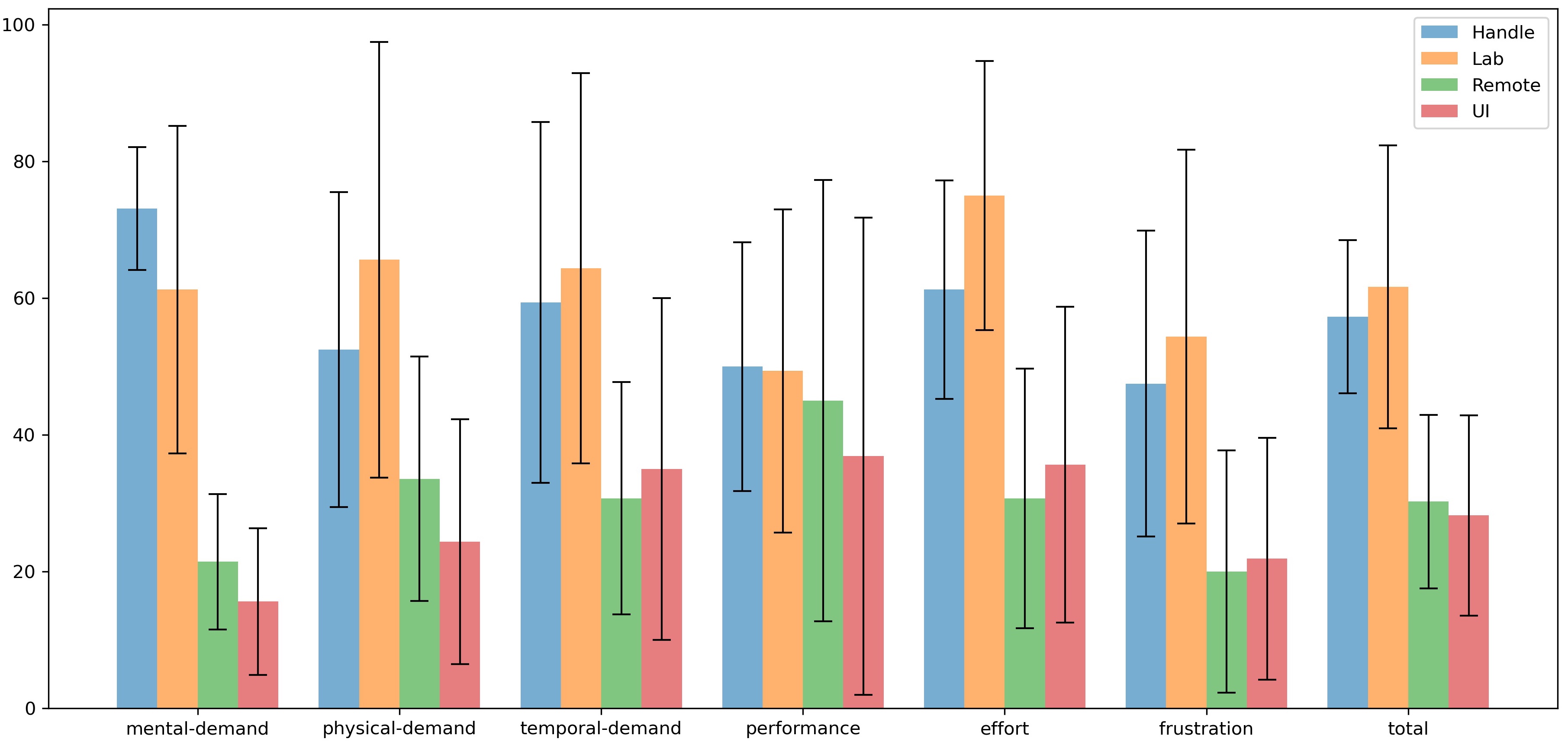
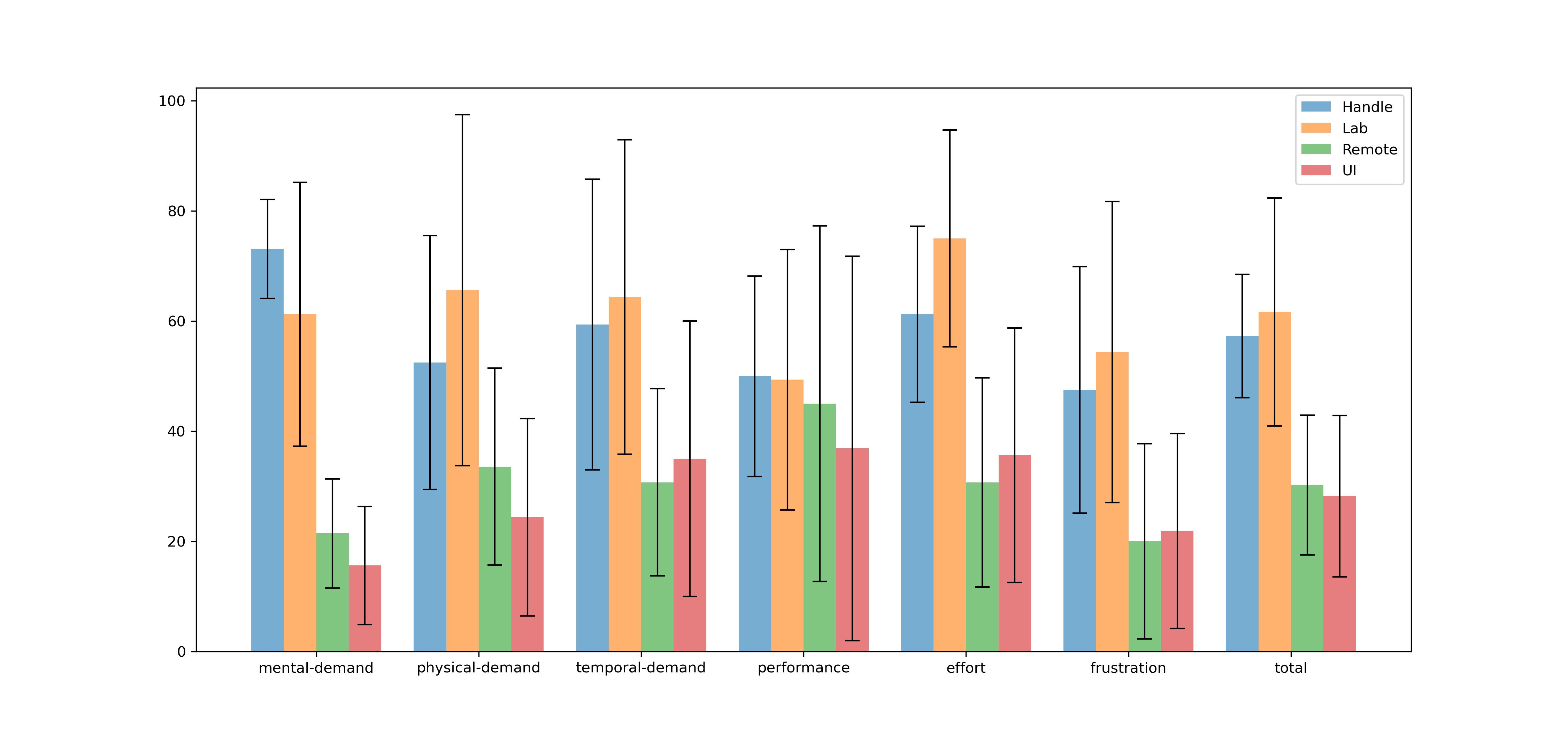
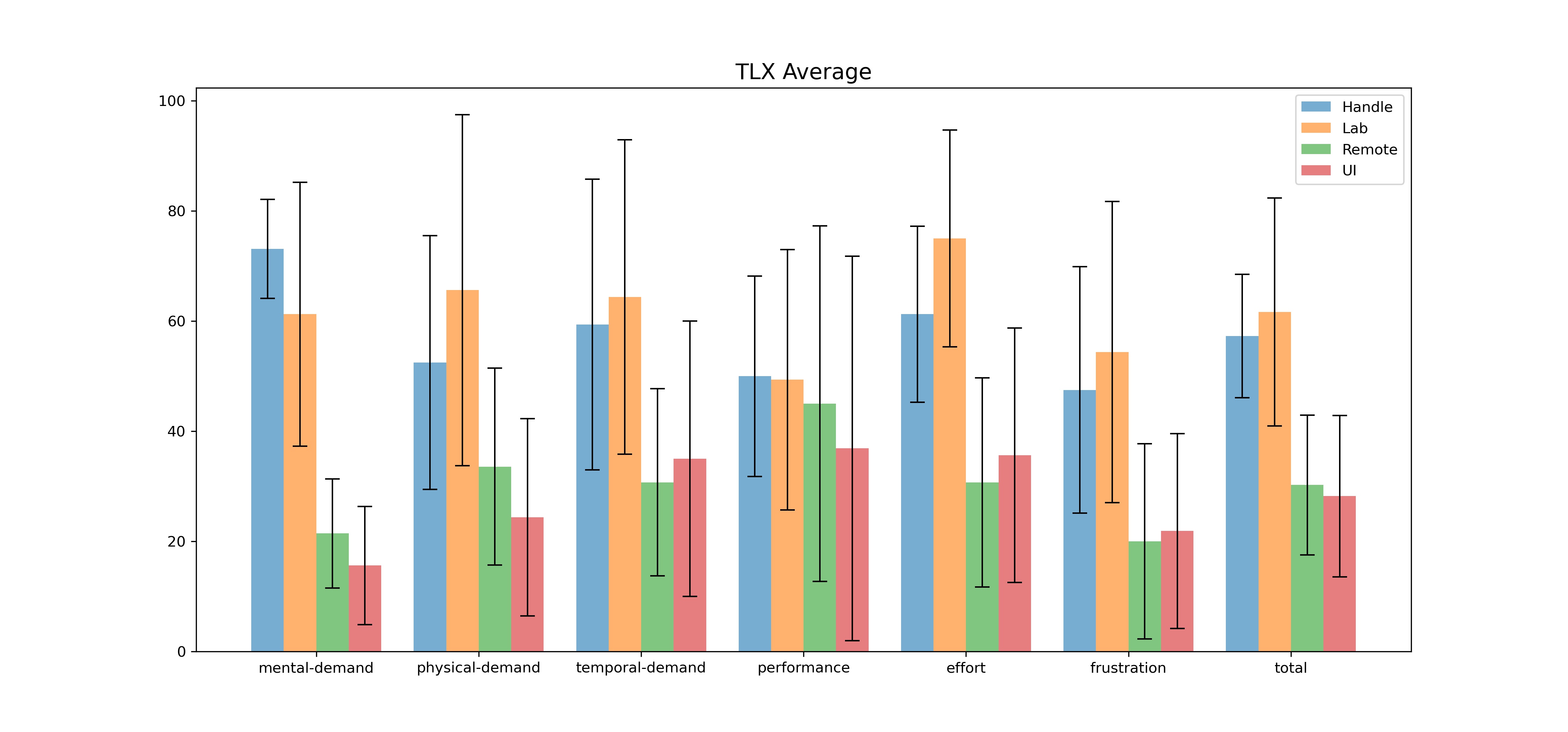
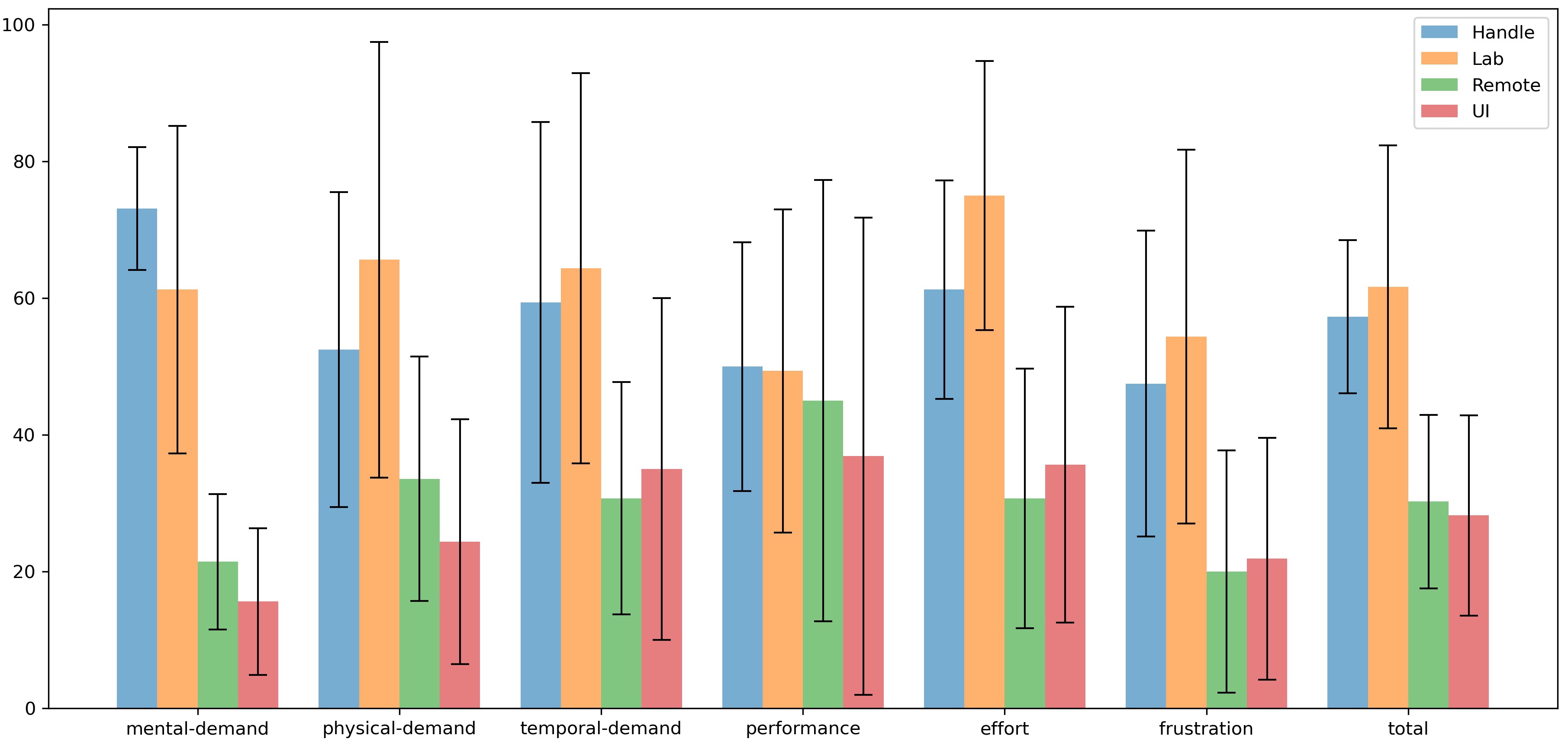
-###### TLX Score
|
|
|
-
|
|
|
-> explain tlx
|
|
|
->
|
|
|
-> [4 figure for each mode]
|
|
|
->
|
|
|
-> analysis
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-###### Likert Questionnaire Results
|
|
|
-
|
|
|
-> 3 questions:
|
|
|
->
|
|
|
-> [3 figure for each question]
|
|
|
->
|
|
|
-> analysis
|
|
|
-
|
|
|
-A questionnaire was used to get their feedback:
|
|
|
-
|
|
|
-```latex
|
|
|
-\begin{enumerate}
|
|
|
-\item I found it easy to move robot in desired position.
|
|
|
-\item I found it easy to concentrate on controlling the robot.
|
|
|
-\item I found it easy to perceive the details of the environment.
|
|
|
-\end{enumerate}
|
|
|
-```
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-##### Qualitative Results
|
|
|
-
|
|
|
-> reason why like/dislike
|
|
|
->
|
|
|
-> other feedbacks
|
|
|
-
|
|
|
-This section will discuss the feedback from participants. Overall, every participant gave positive comments about operating the robot in a \gls{vr} platform. They thought the proposed system was exciting and did allow them to perceive more details in the post-disaster environment than the traditional video-based manipulation. The feedbackts obtained from each mode will be listed next.
|
|
|
-
|
|
|
-70% of participants ranked Lab Mode as the least preferred mode. Some experimenters were very unaccustomed to using \gls{vr} handles to grasp objects, which makes it difficult for them to operate the robot with virtual joysticks smoothly. For those who have \gls{vr} experience, even without any hints and learning, they subconsciously understood what each button and joystick represented and were able to operate the robot directly. Nevertheless, for the actual rescue experience in the test focus, both kinds of participants responded that the robot's operation was more complex and difficult than the other modes. Participants attributed the reasons to obstacles in the environment. One of the participants said:"There is no physical access to the joystick. So it is slightly tough for me to control the robot." In some cases, when the robot was stuck in a corner, it took them much effort to get the robot out of this situation. Also, since the lab mode uses a simulated screen, the lab mode is not as good as the other three in terms of observing the details of the scene. Participants felt that the simulated screen was blurred, and the frequent switching between multiple screens made them very tired.
|
|
|
-
|
|
|
-%Handle
|
|
|
-Handle mode directly using motion controllers for moving robot, and the user can open and close the two monitoring screen through the button. The evaluation of this operation mode depends in large part on the construction of the motion controllers. More than half of the users thought that the \gls{htc} motion controllers made them less flexible when operating the robot's steering. Participants were often unable to accurately touch the correct position of the touchpad when using it, and it was very likely to be touched by mistake. At the end of the experiment, these participants were additionally invited to re-operate the robot using the \gls{vr} controller with joysticks, and said that using joysticks was easier for them to control the direction. Some participants said that they did not like the two monitoring screens provided by this mode. The additional surveillance screens made them subconsciously distracted to observe them, preventing them from concentrating on the rescue mission. Others, however, thought that the monitor was particularly helpful. As it was very difficult to control the robot while teleporting themselves, they first relied on the monitor screen to drive the robot to a place, and then teleported themselves to the location of the robot. The experiment also found that participants tended to forget that the two monitor screens could be closed, and they usually tried to drag the screens to places where they did not affect their view and dragged them back when they wanted to use them.
|
|
|
-
|
|
|
-Remote Mode and UI Mode that use AI intelligent obstacle avoidance walking algorithm were most well-received. Participants felt that in both modes they did not need to worry about how to control the robot's steering and forward speed, but that the computer was responsible for everything, allowing them to focus on virtual world exploration.
|
|
|
-
|
|
|
-For the UI model, one of the participants remarked: "I can just let the robot follow me. I don't need to think about how to operate the robot. This way I can concentrate on the rescue. " In the experiment, it was observed that all participants did not use the direction buttons and monitoring screens in the virtual menu. At the beginning of the test, they all turned on the follow me function directly and adjusted the robot's driving speed to the maximum. After that, the robot was more like a moveable \gls{lidar} sensor. This therefore leads to the fact that these participants could completely disregard the location of the robot and just explore the \gls{vr} world on their own. One participant in the experiment teleported so fast that when he reached a location and had been waiting for a while, the robot was still on its way. In fact, the problem of not being able to find the robot happens in Handle Mode as well.
|
|
|
-
|
|
|
-In contrast, Remote mode solves this problem of the robot not being in view. One participant stated that “The robot is always in sight, so I don't have to waste extra time looking for the robot. Control of the robot is also very easy.” Another participant reflected that after setting the destination of the trolley operation, he would subconsciously observe the movement of the robots so that the robot was always in his visual field of view. They thought it was very easy in this mode to operate robot. Many participants alternated between using the right and left hand rays, first setting the robot's moving target point with the right hand ray, and then teleporting themselves there with the left hand ray. The security measures set up (remote control) were almost not used in the actual test. When it came to the robot's inability to navigate automatically to the destination, the participants preferred to move the robot by resetting the destination point or moving themselves.
|
|
|
-
|
|
|
-In addition to this, participants were found lost in each of the operational modes. They would forget whether the place was already visited by themselves.
|
|
|
-
|
|
|
-##### Discussion
|
|
|
-
|
|
|
-In this section, some possible modifications will be given based on the data obtained from the tests and the feedback given by the participants. At the end of the section, some ideas for developing an ideal \gls{vr}-based interaction approach for operating robots will be summarized
|
|
|
-
|
|
|
-In general, an ideal \gls{vr}-based robotics operation method should take away complexity from the user as much as possible. For the lab model, as the least favorite model of the participants and the one that they find very complicated and difficult to operate, it can be concluded that unless the \gls{vr} operating system is developed for training operators to learn to operate the robot in a real environment, a lab-like mode of operation is not desirable. If one wants to develop a interaction approach like Handle Mode, the choice of \gls{vr} handle should be taken into account. Motion controllers similar to Oculus Quest and Index are recommended because joysticks are better to operate than touchpads.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-###### obstacle avoidance algorithm
|
|
|
-
|
|
|
-
|
|
|
-Remote Mode and UI Mode that use AI intelligent obstacle avoidance algorithm were well-received. In Remote mode, users set the driving destination by ray. In UI mode, the robot could move directly following the user's position in the virtual world. Participants felt that in both modes they did not need to worry about how to control the robot's steering and forward speed, but that the computer was responsible for everything, allowing them to focus on virtual world exploration. However, both control modes require improvement. First of all, the security measures set up (remote control in Remote Mode, orientation buttons in UI Mode) were not used in the actual test. When it came to the robot's inability to navigate automatically to the destination, the participants preferred to move the robot by resetting the destination point or moving themselves. The UI Mode was rated better than Remote Mode by the participants, but as a bystander, I observed some points that could be dangerous for the robot. When participants turned on Follow function, the robot was more like a moveable \gls{lidar} sensor. They would no longer pay attention to whether the robot would be damaged behind them. If in an actual disaster relief situation, in case of an unexpected event such as a secondary collapse, the user may not be able to detect and take action in time. In addition, both modes are highly dependent on AI intelligent obstacle avoidance algorithms. The proposed system currently uses the \gls{nav} component and simulates a post-disaster scene, instead of reconstructing it by scanning the real site through \gls{lidar}. Therefore, there remains a need for an intelligent obstacle avoidance algorithm when using a real robot. This algorithm should be accurate enough so that the user can entirely rely on the computer to control the robot.
|
|
|
-
|
|
|
-In general, an ideal \gls{vr}-based robotics operation method should take away complexity from the user as much as possible. Moreover, the choice of \gls{vr} handle should be taken into account when developing. Motion controllers similar to Oculus Quest and Index are recommended because joysticks are better to operate than touchpads. Some limitations are also worth noting. Because the number of participants was only eight, and most of them had no experience with \gls{vr}, the data tested and the conclusions drawn might not be entirely correct. After professional training, when users can operate \gls{vr} equipment flexibly, some features that are now considered redundant may instead be helpful in practical use.
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-###### Screen 减少
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-###### Map定位机器人,表明自己走过的路径
|
|
|
-
|
|
|
-# Conclusion
|
|
|
-
|
|
|
-> ##### What I have done (overview)
|
|
|
->
|
|
|
-> ###### Unity Project
|
|
|
->
|
|
|
-> - 4 operation modes
|
|
|
->
|
|
|
-> - test scenes
|
|
|
->
|
|
|
->
|
|
|
->
|
|
|
-> ###### User Study
|
|
|
->
|
|
|
-> - compared and evaluated .....
|
|
|
-> - results: .......
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
-> ##### Future work
|
|
|
->
|
|
|
-> - communication with ROS
|
|
|
-> - Real Robots
|
|
|
-> - Use real scene: reconstructed 3D model based on the daten from robot sensors
|
|
|
-
|


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}