|
|
@@ -25,10 +25,15 @@ def predict(src2month):
|
|
|
pkg_num = len(src2month)
|
|
|
training_num = len(src2month['linux'])
|
|
|
|
|
|
+ trainXdict = dict()
|
|
|
+ trainYdict = dict()
|
|
|
+ testXdict = dict()
|
|
|
+ testYdict = dict()
|
|
|
+
|
|
|
look_back = 4
|
|
|
# create the LSTM network
|
|
|
model = Sequential()
|
|
|
- model.add(LSTM(64, input_dim=look_back, activation ='relu', dropout_W =0.1, dropout_U =0.1))
|
|
|
+ model.add(LSTM(32, input_dim=look_back, activation ='relu', dropout_W =0.1, dropout_U =0.1))
|
|
|
# model.add(Dense(12, init='uniform', activation='relu'))
|
|
|
# model.add(Dense(8, init='uniform', activation='relu'))
|
|
|
# model.add(Dense(1, init='uniform', activation='sigmoid'))
|
|
|
@@ -40,9 +45,52 @@ def predict(src2month):
|
|
|
|
|
|
flag = True
|
|
|
###################################################################################################
|
|
|
- for pkg_name in ['icedove', 'linux', 'mysql', 'xulrunner', 'wireshark', 'firefox', 'openjdk', 'php5', 'iceape', 'wordpress', 'xen', 'openssl', 'chromium-browser']:
|
|
|
-# for pkg_name in ['chromium-browser']:
|
|
|
+ for pkg_name in src2month:
|
|
|
+# for pkg_name in ['icedove', 'mysql', 'xulrunner', 'wireshark', 'firefox', 'openjdk', 'php5', 'iceape', 'wordpress', 'xen', 'openssl', 'chromium-browser', 'linux']:
|
|
|
+# for pkg_name in ['linux']:
|
|
|
pkg_num = len(src2month)
|
|
|
+ dataset = src2month[pkg_name]
|
|
|
+
|
|
|
+ if sum(dataset)>20:
|
|
|
+
|
|
|
+ dataset = pandas.rolling_mean(dataset, window=12)
|
|
|
+ dataset = dataset[12:]
|
|
|
+
|
|
|
+ # normalize the dataset
|
|
|
+ dataset = scaler.fit_transform(dataset)
|
|
|
+
|
|
|
+ train_size = int(len(dataset) * 0.80)
|
|
|
+ test_size = len(dataset) - train_size
|
|
|
+ train, test = dataset[0:train_size], dataset[train_size:len(dataset)]
|
|
|
+ print(len(train), len(test))
|
|
|
+
|
|
|
+ # reshape into X=t and Y=t+1
|
|
|
+ trainX, trainY = create_dataset(train, look_back)
|
|
|
+ testX, testY = create_dataset(test, look_back)
|
|
|
+
|
|
|
+ # reshape input to be [samples, time steps, features]
|
|
|
+ trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
|
|
|
+ testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
|
|
|
+
|
|
|
+ # save to dict for later
|
|
|
+ trainXdict[pkg_name], trainYdict[pkg_name] = trainX, trainY
|
|
|
+ testXdict[pkg_name], testYdict[pkg_name] = testX, testY
|
|
|
+
|
|
|
+ # fit the LSTM network
|
|
|
+ model.fit(trainX, trainY, nb_epoch=10, batch_size=1, verbose=2)
|
|
|
+
|
|
|
+
|
|
|
+###################################################################################################
|
|
|
+
|
|
|
+
|
|
|
+ model.save('all_packages_test.h5')
|
|
|
+
|
|
|
+
|
|
|
+ for pkg_name in ['icedove', 'mysql', 'xulrunner', 'wireshark', 'firefox', 'openjdk', 'php5', 'iceape', 'wordpress', 'xen', 'openssl', 'chromium-browser', 'linux']:
|
|
|
+
|
|
|
+ trainX, trainY = trainXdict[pkg_name], trainYdict[pkg_name]
|
|
|
+ testX, testY = testXdict[pkg_name], testYdict[pkg_name]
|
|
|
+
|
|
|
dataset = src2month[pkg_name]
|
|
|
dataset = pandas.rolling_mean(dataset, window=12)
|
|
|
dataset = dataset[12:]
|
|
|
@@ -50,52 +98,34 @@ def predict(src2month):
|
|
|
# normalize the dataset
|
|
|
dataset = scaler.fit_transform(dataset)
|
|
|
|
|
|
- train_size = int(len(dataset) * 0.80)
|
|
|
- test_size = len(dataset) - train_size
|
|
|
- train, test = dataset[0:train_size], dataset[train_size:len(dataset)]
|
|
|
- print(len(train), len(test))
|
|
|
|
|
|
- # reshape into X=t and Y=t+1
|
|
|
- trainX, trainY = create_dataset(train, look_back)
|
|
|
- testX, testY = create_dataset(test, look_back)
|
|
|
-
|
|
|
- # reshape input to be [samples, time steps, features]
|
|
|
- trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
|
|
|
- testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
|
|
|
|
|
|
- # fit the LSTM network
|
|
|
- model.fit(trainX, trainY, nb_epoch=5, batch_size=1, verbose=2)
|
|
|
-
|
|
|
-
|
|
|
-###################################################################################################
|
|
|
+ # make predictions
|
|
|
+ trainPredict = model.predict(trainX)
|
|
|
+ testPredict = model.predict(testX)
|
|
|
+ # invert predictions
|
|
|
+ trainPredict = scaler.inverse_transform(trainPredict)
|
|
|
+ trainY = scaler.inverse_transform([trainY])
|
|
|
+ testPredict = scaler.inverse_transform(testPredict)
|
|
|
+ testY = scaler.inverse_transform([testY])
|
|
|
+ # calculate root mean squared error
|
|
|
+ print('Package: ' + pkg_name)
|
|
|
+ trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
|
|
|
+ print('Train Score: %.2f RMSE' % (trainScore))
|
|
|
+ testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
|
|
|
+ print('Test Score: %.2f RMSE' % (testScore))
|
|
|
|
|
|
|
|
|
- # make predictions
|
|
|
- trainPredict = model.predict(trainX)
|
|
|
- testPredict = model.predict(testX)
|
|
|
- print(type(testPredict))
|
|
|
- # invert predictions
|
|
|
- trainPredict = scaler.inverse_transform(trainPredict)
|
|
|
- trainY = scaler.inverse_transform([trainY])
|
|
|
- testPredict = scaler.inverse_transform(testPredict)
|
|
|
- testY = scaler.inverse_transform([testY])
|
|
|
- # calculate root mean squared error
|
|
|
- trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
|
|
|
- print('Train Score: %.2f RMSE' % (trainScore))
|
|
|
- testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
|
|
|
- print('Test Score: %.2f RMSE' % (testScore))
|
|
|
-
|
|
|
-
|
|
|
- # shift train predictions for plotting
|
|
|
- trainPredictPlot = numpy.empty_like(dataset)
|
|
|
- trainPredictPlot[:] = numpy.nan
|
|
|
- trainPredictPlot[look_back:len(trainPredict)+look_back] = trainPredict[:, 0]
|
|
|
- # shift test predictions for plotting
|
|
|
- testPredictPlot = numpy.empty_like(dataset)
|
|
|
- testPredictPlot[:] = numpy.nan
|
|
|
- testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1] = testPredict[:, 0]
|
|
|
- # plot baseline and predictions
|
|
|
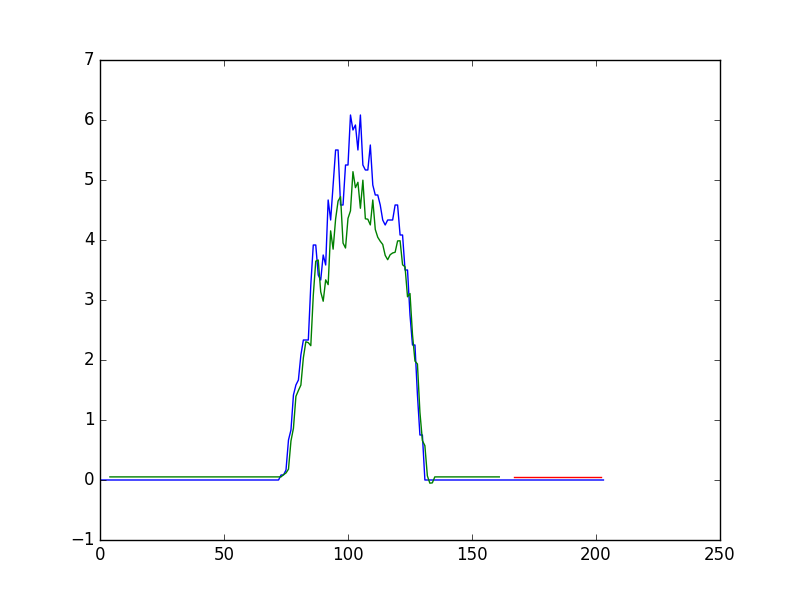
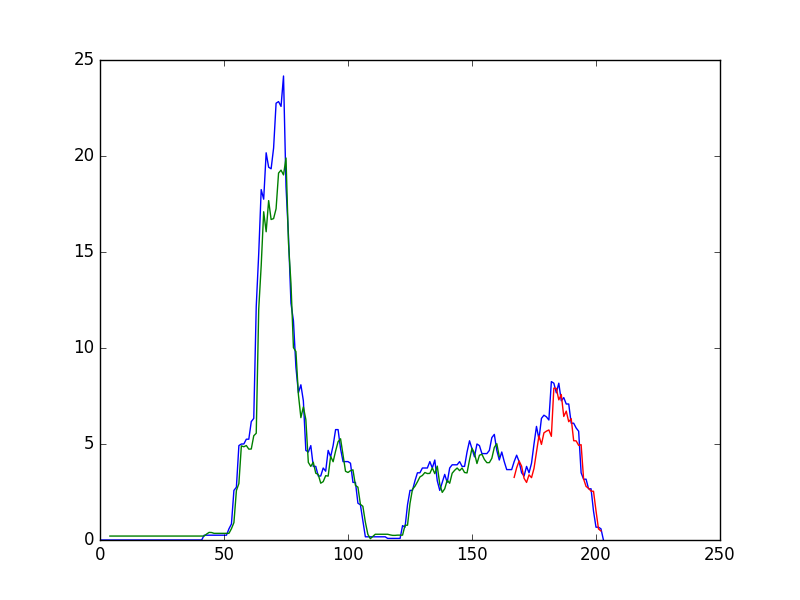
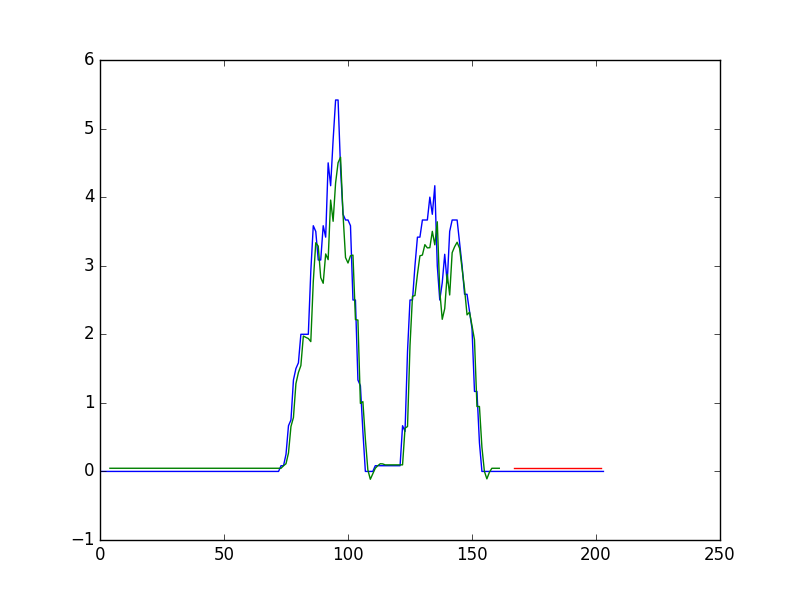
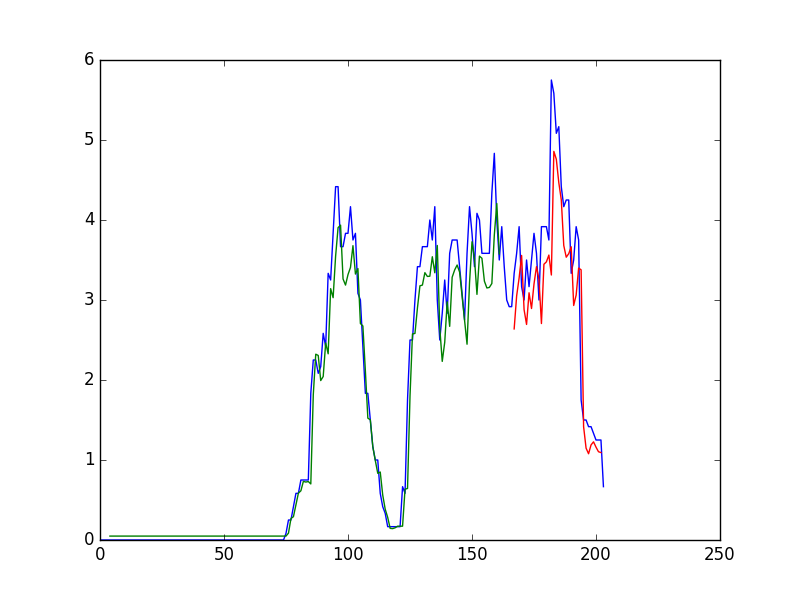
- plt.plot(scaler.inverse_transform(dataset))
|
|
|
- plt.plot(trainPredictPlot)
|
|
|
- plt.plot(testPredictPlot)
|
|
|
- plt.show()
|
|
|
+ # shift train predictions for plotting
|
|
|
+ trainPredictPlot = numpy.empty_like(dataset)
|
|
|
+ trainPredictPlot[:] = numpy.nan
|
|
|
+ trainPredictPlot[look_back:len(trainPredict)+look_back] = trainPredict[:, 0]
|
|
|
+ # shift test predictions for plotting
|
|
|
+ testPredictPlot = numpy.empty_like(dataset)
|
|
|
+ testPredictPlot[:] = numpy.nan
|
|
|
+ testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1] = testPredict[:, 0]
|
|
|
+ # plot baseline and predictions
|
|
|
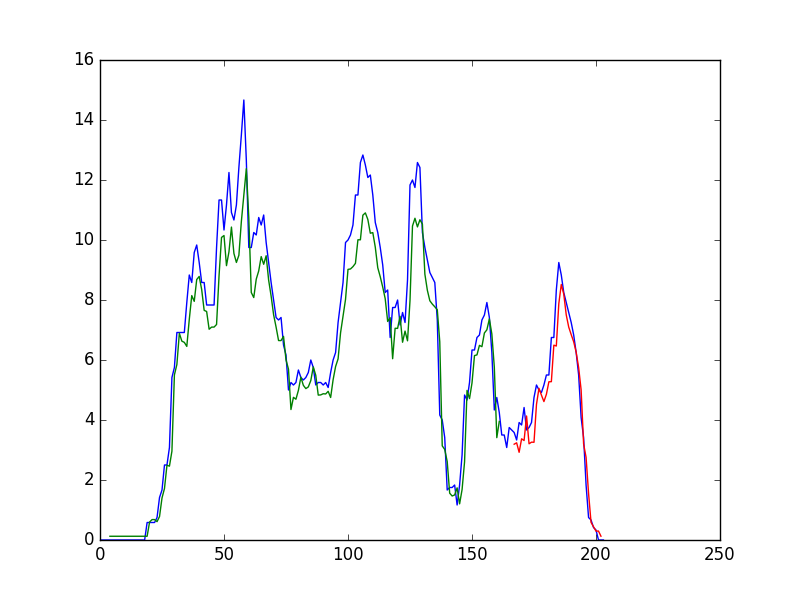
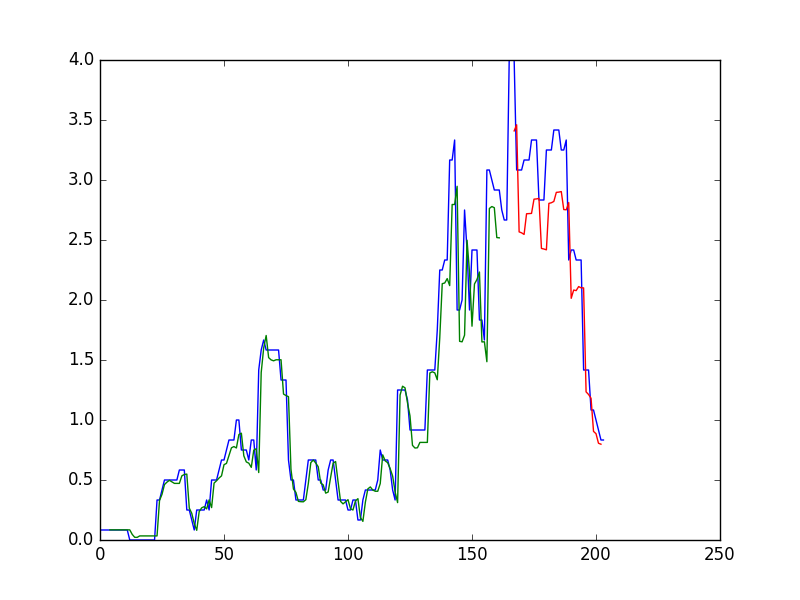
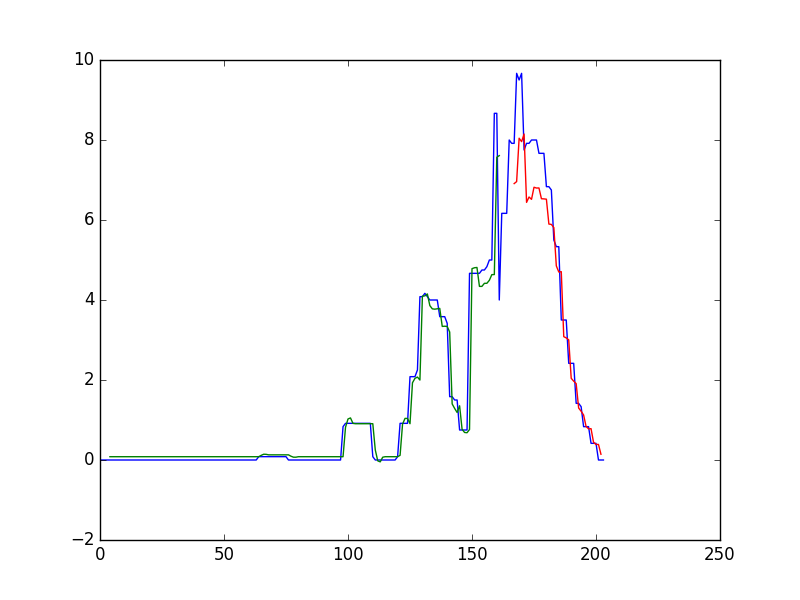
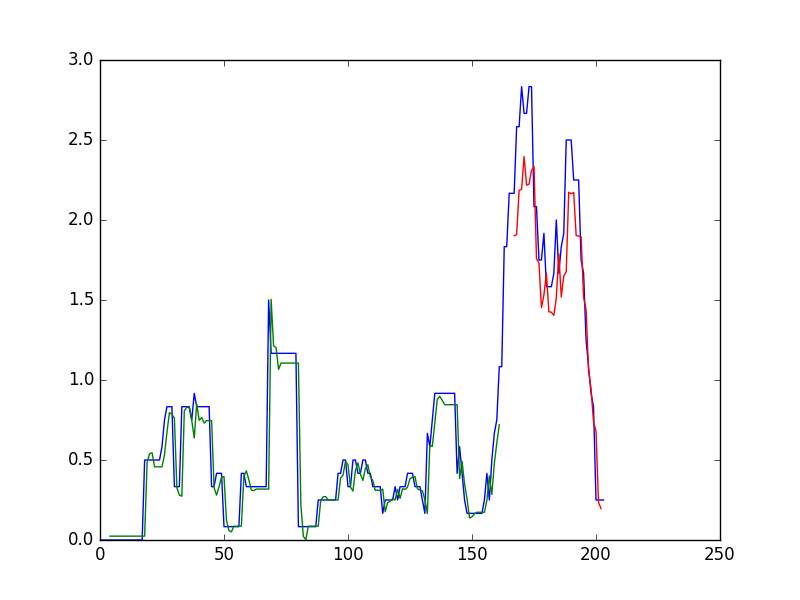
+ plt.plot(scaler.inverse_transform(dataset))
|
|
|
+ plt.plot(trainPredictPlot)
|
|
|
+ plt.plot(testPredictPlot)
|
|
|
+ plt.show()
|


{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}