|
|
@@ -1,85 +1,35 @@
|
|
|
\chapter{Proof of Concept}
|
|
|
\label{ch:proof-of-concept}
|
|
|
+\input{content/05-proof-of-concept/introduction}
|
|
|
|
|
|
-The ideas for a hybrid OSN presented in Chapter 4 were implemented with the development of a prototype. The resulting hybrid client for Twitter is presented in this chapter and the important design decisions are presented in a comprehensible way. Essential aspects such as the choice of OSN, the choice of technologies used to develop the app and important features of the client are explained.
|
|
|
+\section{Objective}
|
|
|
+\label{sec:objective}
|
|
|
+\input{content/05-proof-of-concept/objective}
|
|
|
|
|
|
-\section{Choosing an OSN}
|
|
|
-\label{sec:choose-osn}
|
|
|
+\section{Selection of the OSN}
|
|
|
+\label{sec:osn-selection}
|
|
|
+\input{content/05-proof-of-concept/osn-selection}
|
|
|
|
|
|
-When selecting a suitable OSN for the development of a hybrid client, Facebook was the obvious choice due to the numerous negative headlines about data protection. With over 2 billion users per month, it is currently the most widely used social network in the world. In the recent past, it has often been criticized for its handling of its users' data. In particular, the scandal surrounding the data analysis company Cambridge Analytica, which had access to the data of up to 87 million Facebook users, hit Facebook hard. As a result, CEO Mark Zuckerberg had to face the US Congress and the EU Parliament in question rounds and did not leave a good impression by avoiding many questions. As a result of this scandal, the Facebook API was further restricted.
|
|
|
+\section{Technology Decisions}
|
|
|
+\label{sec:technology-decisions}
|
|
|
+\input{content/05-proof-of-concept/technology-decisions}
|
|
|
|
|
|
-However, the Facebook API is not suitable for developing your own client anyway. The functionalities offered by the API offer the possibility to develop an app that can be used within Facebook. For example, it's not possible to make a like for a post using this API. As discussed in chapter 4, it is possible to access the data through crawling. However, the constant and rapid development would make this an arduous undertaking. In a blog entry\footnote{https://code.fb.com/web/rapid-release-at-massive-scale/} Facebook writes that the code changes every few hours. So it is almost impossible to adjust the crawler fast enough and roll out the adjusted code.
|
|
|
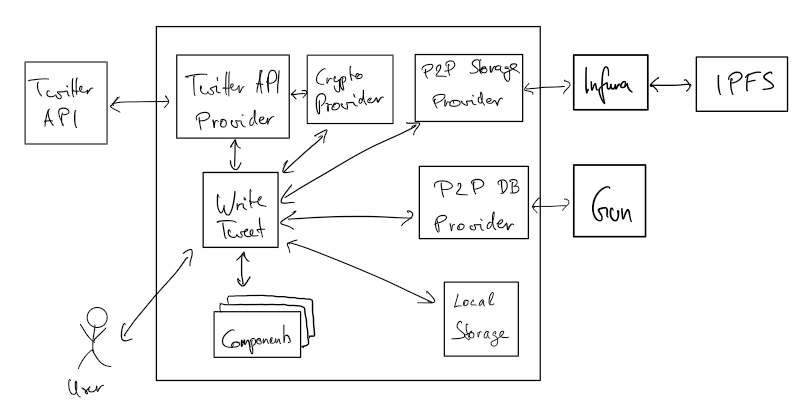
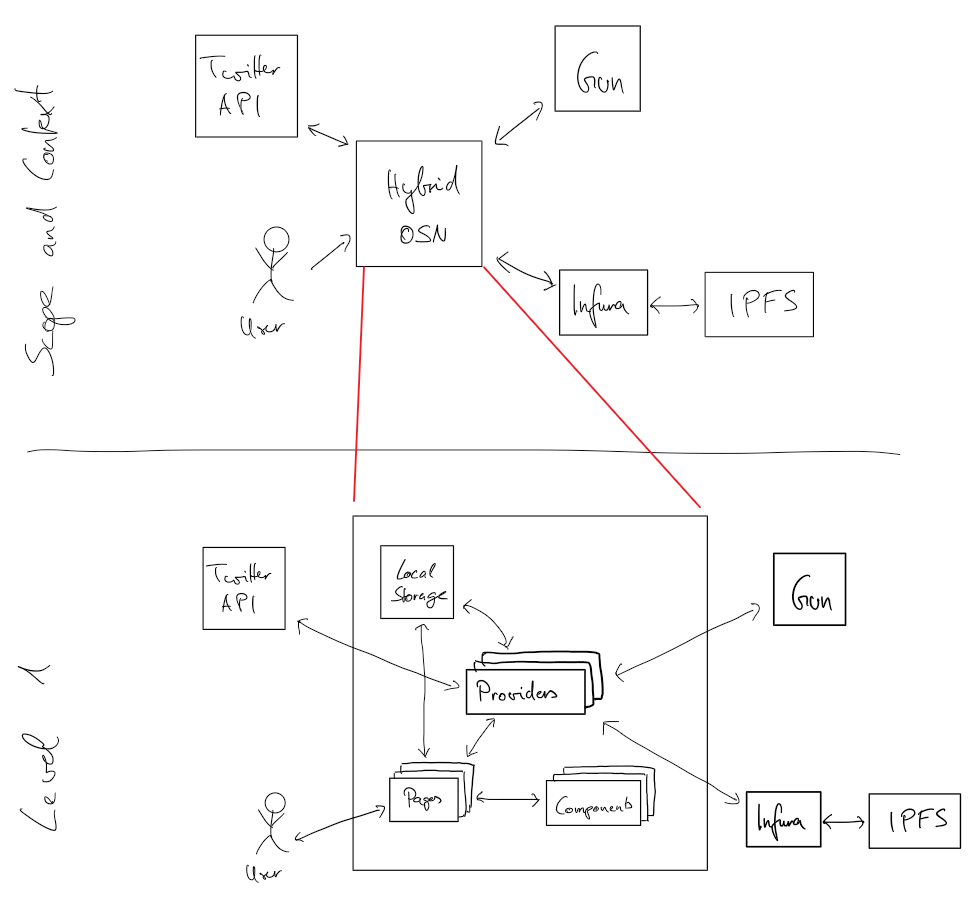
+\section{Building Block View}
|
|
|
+\label{sec:building-block-view}
|
|
|
+\input{content/05-proof-of-concept/building-block-view}
|
|
|
|
|
|
-If you take a look at the app stores, you will find alternative Facebook clients (e.g. \enquote{Friendly for Facebook}\footnote{https://play.google.com/store/apps/details?id=io.friendly} \footnote{https://itunes.apple.com/de/app/friendly-for-facebook/id400169658}, \enquote{Metal Pro}\footnote{https://play.google.com/store/apps/details?id=com.nam.fbwrapper.pro}). Because Facebook doesn't provide an API and crawling isn't an alternative, these clients must have found a different way. This other way is to display the mobile Facebook page\footnote{https://m.facebook.com/} and manipulate it with injected CSS and JavaScript files. The app itself therefore only offers a container around the mobile Facebook website and modifies it. The changes then often refer only to color changes and links to frequently used pages. In order to adapt the design, knowledge of the page structure and the structure of individual components is necessary. Facebook's fast and frequent code adjustments lead to the fact that the design changes of the app do not work in some places and have to struggle with the same problems as with crawling.
|
|
|
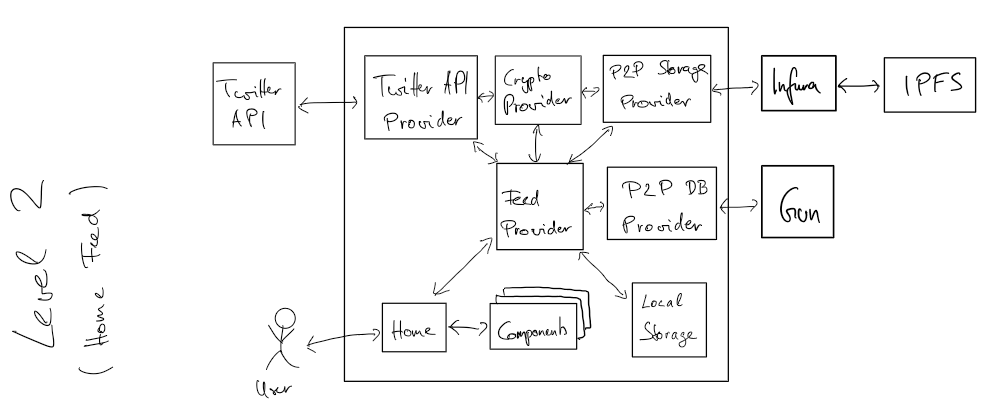
+\section{Runtime View}
|
|
|
+\label{sec:runtime-view}
|
|
|
+\input{content/05-proof-of-concept/runtime-view}
|
|
|
|
|
|
-For this number of reasons, Facebook was dropped as OSN for the prototype, despite special interest. Another candidate was the OSN Google Plus, because Google announced in October 2018\footnote{https://www.blog.google/technology/safety-security/project-strobe/} it will discontinue its OSN.
|
|
|
+\section{Security}
|
|
|
+\label{sec:security}
|
|
|
+\input{content/05-proof-of-concept/security}
|
|
|
|
|
|
-Ultimately, the OSN's choice for the prototype fell on Twitter. With 336 million active users per month, it is one of the largest social networks. It is particularly well suited for the development of a hybrid client for two reasons: on the one hand, it has a detailed API that provides almost the full functionality free of charge, and on the other hand, compared to Facebook, it offers only a few simple functions. These are the ideal prerequisites for a first proof of concept. In order to use the API, an application must be registered for which an API key is then assigned. This API key entitles the user to use the API and must be sent with every request to the API in the request header. Use of the API is limited. The limitation depends on the app and the user.
|
|
|
+\section{Providing Insights to the Service Provider}
|
|
|
+\label{sec:insights}
|
|
|
+\input{content/05-proof-of-concept/insights}
|
|
|
|
|
|
-\section{Twitter API}
|
|
|
-\label{sec:twitter-api}
|
|
|
-
|
|
|
-Twitter offers different APIs for developers that serve different purposes. The current APIs are:
|
|
|
-\begin{itemize}
|
|
|
- \item \textbf{Standard API}: the free and public API offering basic query functionality and foundational access to Twitter data.
|
|
|
- \item \textbf{Premium API}: introduced in November 2017 to close the gap between Standard and Entrprise API. Improvements over the standard API: \enquote{more Tweets per request, higher rate limits, a counts endpoint that returns time-series counts of Tweets, more complex queries and metadata enrichments, such as expanded URLs and improved profile geo information}\footnote{https://blog.twitter.com/developer/en\_us/topics/tools/2017/introducing-twitter-premium-apis.html}. Prices to use this API start at 149\$/month.
|
|
|
- \item \textbf{Enterprise API}:
|
|
|
- \item \textbf{Ads API}: this API is only of interest for creating and managing ad campaigns.
|
|
|
- \item \textbf{Twitter for websites}: this is more a suite of tools than an API. It's free to use and enables people to embed tweets and tweet buttons on their website.
|
|
|
-\end{itemize}
|
|
|
-
|
|
|
-In the case of the hybrid client, the standard API is the right one. In order to use this API you first have to create a \enquote{Twitter App}. After registering you will get a consumer key and access token. These two authentication tokens are required to log in users via their own app and successfully execute requests to the API.
|
|
|
-
|
|
|
-Twitter offers almost the entire range of functions via the API. The lack of functionalities (such as querying Reply to a Tweet or the search results come only from the last days) are not so difficult. A major limitation is the limitation on the number of requests. This is to prevent Twitter being exposed to too much load. It also aims to prevent bots from abusing Twitter. The exact limits can be found on a help page\footnote{https://developer.twitter.com/en/docs/basics/rate-limits}. In the app stores of Google and Apple, there are a number of alternative Twitter clients (Twitterific\footnote{https://itunes.apple.com/de/app/twitterrific-5-for-twitter/id580311103?mt=8}, [more examples ...]), which are also subject to these restrictions in terms of functionality and limitation.
|
|
|
-
|
|
|
-Basically, the API can be used via http requests. The data exchanged are available in JSON format. However, there are also various libraries, some of which are developed directly by Twitter and greatly simplify the use of the API.
|
|
|
-
|
|
|
-\section{P2P Network}
|
|
|
-\label{sec:p2p-network}
|
|
|
-Now Twitter is to be extended by a P2P network through which data can be exchanged safely and in particular without the knowledge of Twitter. Basically, there are two conceivable approaches for the P2P network:
|
|
|
-
|
|
|
-\begin{itemize}
|
|
|
- \item Creation of a separate P2P network between the hybrid client apps
|
|
|
- \item Use of an existing P2P network for your own purposes
|
|
|
-\end{itemize}
|
|
|
-
|
|
|
-These two approaches are presented and discussed below.
|
|
|
-
|
|
|
-\subsection{Creation of a P2P network}
|
|
|
-\label{sec:create-p2p-network}
|
|
|
-
|
|
|
-The advantage of having your own P2P network is that you have it completely under control. Accordingly, it can be designed to fit exactly to the use case and require little or no compromise. However, setting up your own P2P network is a big challenge and some hurdles must be overcome. These challenges include peer discovery (how peers find each other), global data exchange over the Internet and data storage, and availability of the stored data. And of course, all these requirments must scale so it will work for P2P networks with only a few peers and also for a few thousand or even more peers. Two approaches are conceivable here: the use of an established standard such as Wi-Fi Dircet or WebRTC or the use of a library (for example Hive2Hive, Y-Js) to create a dedicated P2P network.
|
|
|
-
|
|
|
-\subsubsection{Wi-Fi Direct}
|
|
|
-Wi-Fi Direct is a standard (IEEE 802.11) for data transmission between two WLAN terminals. There is no need for an access point between the two devices. However, the distance that may lie between the two peers is thus limited. Without obstacles, which contribute to the attenuation of the signal, a distance of up to 95m is possible. In buildings, it sinks to 32m or less. However, the requirement for the P2P network to expand Twitter is different. Users can be scattered around the world and may be online through the mobile network. There is no P2P connection via Wi-Fi Dircet in this case.
|
|
|
-
|
|
|
-\subsubsection{WebRTC}
|
|
|
-WebRTC (Web Real-Time Communication) is an open standard that provides various communication protocols for real-time communication between two or more peers. Above all, WebRTC is popular for its ability to easily perform video calls, as known from Skype, in the browser without a server. But also the file transfer between peers is possible. In a separate P2P network, data could be exchanged between the clients. However, the connection between the clients is complex, since in addition to the two peers also a STUN server and optionally a TURN server is involved. Furthermore, it is unclear whether the system scales. At least for Google Chrome browser is known that a maximum of 265 connections to other peers can be maintained in parallel.
|
|
|
-
|
|
|
-\subsubsection{Y-JS}
|
|
|
-The JavaScript library Y-JS describes itself as \enquote{a framework for offline-first p2p shared editing on structured data-like text, richtext, json, or XML.} The library takes care of solving synchronization conflicts when editing distributed files. By choosing a connector, you can set the protocol for the communication between the peers.There is the possibility to use WebRTC, XMPP or Websockets, but with some connectors running a server is a prerequisite. Further extensions can be used to supplement a database and data types, but the focus here is on the joint editing of data by multiple peers. For all connectors, the authors of the library recommend using an own server.
|
|
|
-
|
|
|
-\subsubsection{Hive2Hive}
|
|
|
-Hive2Hive is a Java library for \enquote{secure, distributed, P2P-based file synchronization and sharing}. There is no less promise than \enquote{a free and open-sourced, distributed and scalable solution that focuses on maximum security and privacy of both users and data}. In order to be able to use Hive2Hive globally via the Internet, it is necessary to operate at least one relay peer - five are recommended\footnote{https://github.com/Hive2Hive/Android/wiki/Guide-for-System-Admins}. Since a permanent TCP connection between peer and relay peer is maintained, the power consumption is quite high. Constant TCP connection can be avoided by using Google Cloud Messaging (GCM). However, Google has already discontinued this service. And since the development of Hive2Hive was discontinued in March 2015 too, there is currently no solution to this problem.
|
|
|
-
|
|
|
-\subsubsection{GUN}
|
|
|
-GUN is a graph database that keeps a state in sync across multiple instances. GUN is written in JavaScript and unlike Hive2Hive and Y-JS, the project is still being worked on.
|
|
|
-
|
|
|
-\textit{todo...}
|
|
|
-
|
|
|
-\subsubsection{Conclusion}
|
|
|
-While there are ways to build your own P2P network and exchange data about it, this can only be done on a local level easily. Although there is a standard with WebRTC that can connect multiple clients, this is not appropriate for a P2P network to extend an OSN due to its lack of scalability. To keep data available and to ensure successful and effective peer discovery, running your own infrastructure with servers permanently accessible from a static address is inevitable. The benefits of an always reachable server and the low cost of operation could be one of the reasons why P2P solutions are so unpopular and there are only few outdated libraries.
|
|
|
-
|
|
|
-\subsection{Using an Existing P2P Network}
|
|
|
-\label{sec:using-existing-p2p-network}
|
|
|
-As mentioned in the previous section, setting up your own P2P network involves a number of challenges. If you use an already existing P2P network for your own purpose, these challenges can be elegantly avoided. For this purpose, however, a suitable P2P network must be found whose properties and possible uses meet the requirements of the hybrid OSN client.
|
|
|
-
|
|
|
-In the following, various P2P networks are considered and examined for their usability for a potential deployment to extend an OSN. It is based on the requirements set out in the previous chapter.
|
|
|
-
|
|
|
-\subsubsection{Filesharing P2P Networks}
|
|
|
-
|
|
|
-\subsubsection{Distributed Apps - Blockchain}
|
|
|
-
|
|
|
-\subsubsection{Conclusion}
|
|
|
\section{Summary}
|
|
|
-\label{sec:proof-of-concept-summary}
|
|
|
+\label{sec:proof-of-concept-summary}
|
|
|
+\input{content/05-proof-of-concept/summary}
|


{kind=link}
{kind=link}
{kind=link}
{kind=link}